Ricevi la newsletter
Tool, prompt e workflow AI. Una volta a settimana, gratis.
Sei dentro. Da questa settimana ricevi la newsletter.
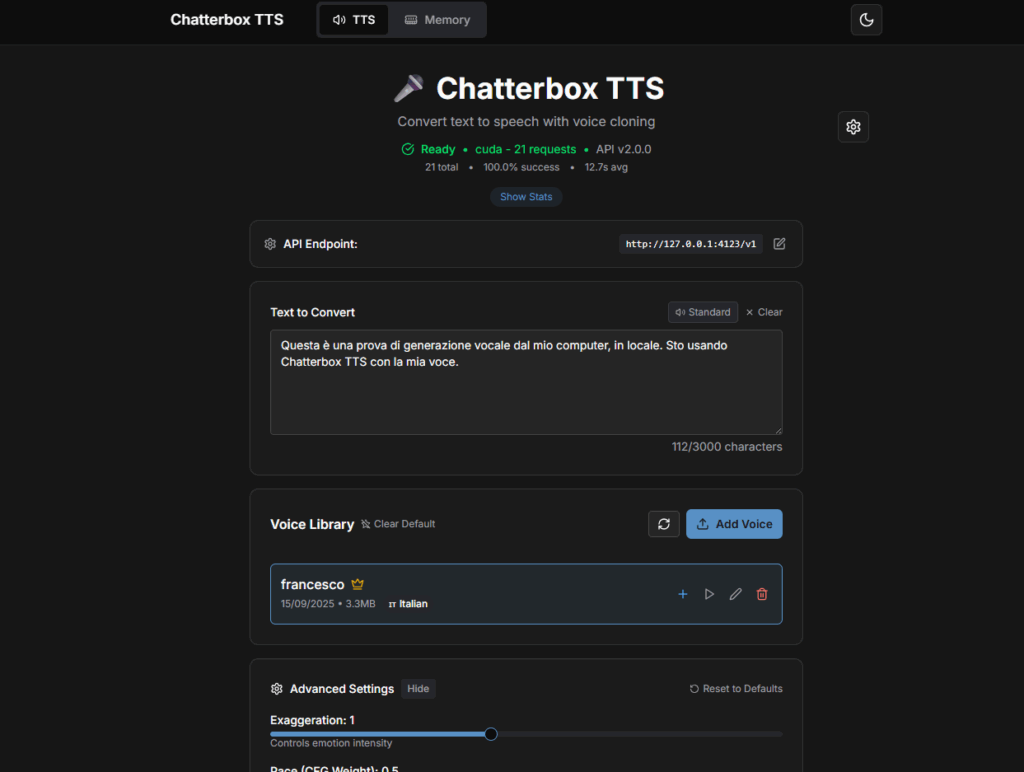
Installa e testa Chatterbox TTS in locale su Windows con Docker/WSL2: CPU o GPU, frontend Nginx, upload voce, streaming e primi test API.

Negli ultimi mesi sto facendo un giro d’orizzonte sui Text-to-Speech locali, per capire cosa abbia senso usare “on-prem” quando privacy, latenza e costi ricorrenti contano più di tutto. In questo post metto sotto la lente Chatterbox TTS, un progetto open che espone un’API stile OpenAI e supporta la clonazione voce e lo streaming.
Sul mio hardware (Windows 11 + Docker Desktop/WSL2, RTX 3050 Ti 4 GB e 64 GB RAM) Chatterbox TTS gira bene in locale. Con GPU l’inferenza è nettamente più vivace rispetto alla CPU (che per una frase breve arrivava anche a ~60s), ma per l’italiano oggi sento ancora un accento inglese e un timbro un po’ metallico anche clonando la mia voce. Non è “pronto per doppiaggio”, però è promettente e lo terrò in test continuo.
Ricevi una guida pratica ogni settimana. AI, tool e automazioni.
cuda)VITE_API_BASE puntato all’APINota: per chi usa Docker su Windows, l’API gira dentro docker-desktop (WSL2). Il processo VmmemWSL può salire di RAM: è normale durante il primo warm-up modello.
GET /languages → 22 (italiano incluso).POST /voices (es. italian_sample.wav) e verificate con GET /voices./audio/speech e streaming su /audio/speech/stream con chunking per frase.Nella UI, questi range hanno dato i risultati più naturali:
Se senti “sibilanti” o cantilena inglese, abbassa un filo Exaggeration e Temperature, e tieni CFG sotto 0.4.
La parte più importante. Con campioni voce personali puliti (WAV 16-48 kHz, 16-bit, senza musica/riverbero, 30–60 s), la somiglianza timbrica c’è, ma:
Non è un problema di pipeline: è proprio lo stato attuale del modello multilingua. Se il tuo target è assistenti vocali, demo interne o prototipi va già bene; per voice-over pubblicitari o doppiaggio serve ancora un salto.
Se ti serve, ho preparato un copione sample per caricare una voce “ricca” di fonemi italiani (lo trovi nella guida).
chatterbox-tts) nell’upstream Nginx.http://host.docker.internal:4123 (Windows/Mac) o all’IP della macchina.-e VITE_API_BASE=http://host.docker.internal:4123 e usa l’Nginx già configurato per servire gli asset statici.curl con -H e -d danno errore in PS se copiati “alla Linux”.curl.exe e json con --data/-d tra apici doppi, oppure fai le chiamate con Python/requests.host.docker.internal:4123.VITE_API_BASE mancante.Chatterbox TTS è già oggi un buon candidato per chi vuole un TTS locale multilingua con una vera voice library ed endpoint comodi.
Nel mio uso reale:
Io lo terrò in produzione “di prova” su GPU e aggiornerò questo post man mano che escono nuovi pesi/preset.
Adesso passiamo al pezzo forte, ovvero la guida completa per rifare esattamente i miei test (CPU e GPU), con frontend Docker e Nginx già pronti, script per upload voce e chiamate streaming. Buon divertimento!
Intanto se vuoi avere maggiori informazioni ti invito ad accedere alla Repo GitHub del progetto.
Iniziamo con il vero setup:
docker-desktop come VM dei container).🔎 Nota WSL: le distro “Ubuntu”/“Ubuntu-22.04” sono facoltative per te. I container girano in
docker-desktop.
cd $HOME
git clone https://github.com/travisvn/chatterbox-tts-api.git
cd chatterbox-tts-apiStruttura che ci interessa:
chatterbox-tts-api/
docker/
docker-compose.cpu.yml
docker-compose.gpu.yml
frontend/
Dockerfile
nginx.confcd docker
docker compose -f docker-compose.cpu.yml up -d --buildchatterbox-tts-api-cpucd docker
# se il container CPU è acceso, spegnilo PRIMA (stesso port 4123)
docker compose -f docker-compose.cpu.yml down
# poi avvia la versione GPU
docker compose -f docker-compose.gpu.yml up -d --buildchatterbox-tts-api-gpuDevice: cuda. Puoi verificare:docker exec -it chatterbox-tts-api-gpu bash -lc "nvidia-smi"curl.exe -s http://127.0.0.1:4123/health
curl.exe -s http://127.0.0.1:4123/openapi.json > NUL
start http://127.0.0.1:4123/docsSe /docs si apre, l’API è pronta.
import requests
files = {
"voice_file": ("italian_sample.wav", open("C:/Users/Francesco/Desktop/tts/italian_sample.wav", "rb"), "audio/wav")
}
data = {
"voice_name": "italian_sample",
"language": "it"
}
response = requests.post("http://localhost:4123/voices", data=data, files=files)
print(f"Upload status: {response.status_code}, response: {response.text}")import requests
url = "http://localhost:4123/audio/speech"
headers = {"accept": "audio/wav", "Content-Type": "application/json"}
data = {
"input": "Ciao, come stai? Tutto bene? Questo è un test di generazione vocale.",
"voice": "italian_sample",
"response_format": "wav",
"speed": 1.0,
"exaggeration": 0.5,
"cfg_weight": 0.5,
"temperature": 0.75
}
r = requests.post(url, headers=headers, json=data)
if r.ok:
with open("output_italian.wav", "wb") as f:
f.write(r.content)
print("Audio salvato come output_italian.wav")
else:
print(r.status_code, r.text)Costruiamo l’immagine e lanciamo un container Nginx statico.
cd ..\frontend
docker build -t chatterbox-tts-frontend .In Windows, il frontend deve parlare con l’API host usando host.docker.internal:
docker run --name tts-frontend --rm -p 8080:80 `
-e VITE_API_BASE=http://host.docker.internal:4123 `
chatterbox-tts-frontendApri http://localhost:8080 → ora il frontend chiama correttamente l’API.
💡 Se preferisci 127.0.0.1 al posto di
host.docker.internal, modifica direttamentenginx.conf(vedi §5).
Se vuoi far parlare Nginx con l’API usando il nome del servizio (chatterbox-tts), serve un compose unico. Esempio minimale:
# docker-compose.app.yml
services:
chatterbox-tts:
build:
context: ..
dockerfile: docker/Dockerfile.cpu # o .gpu per GPU
image: docker-chatterbox-tts
ports:
- "4123:4123"
tts-frontend:
build:
context: ../frontend
image: chatterbox-tts-frontend
ports:
- "8080:80"
environment:
- VITE_API_BASE=http://chatterbox-tts:4123
depends_on:
- chatterbox-ttsPoi:
docker compose -f docker-compose.app.yml up -d --buildUsa questa nginx.conf (è quella che ci ha sbloccato tutto):
server {
listen 80;
server_name localhost;
root /usr/share/nginx/html;
index index.html index.htm;
gzip on; gzip_vary on; gzip_min_length 1024;
gzip_types text/plain text/css text/xml text/javascript application/javascript application/xml+rss application/json;
# API Proxy → backend locale su Windows/Mac:
set $api http://host.docker.internal:4123;
location /v1/ { proxy_pass $api; }
location /health { proxy_pass $api; }
location /config { proxy_pass $api; }
location /models { proxy_pass $api; }
location /memory { proxy_pass $api; }
location /docs { proxy_pass $api; }
location /redoc { proxy_pass $api; }
location /openapi.json { proxy_pass $api; }
# Static cache
location ~* \.(js|css|png|jpg|jpeg|gif|ico|svg|woff2?)$ {
expires 1y;
add_header Cache-Control "public, immutable";
try_files $uri =404;
}
# SPA routing
location / {
try_files $uri $uri/ /index.html;
add_header X-Content-Type-Options nosniff;
add_header X-Frame-Options DENY;
add_header X-XSS-Protection "1; mode=block";
}
# Health del frontend
location /frontend-health { access_log off; return 200 "frontend healthy\n"; }
# Sicurezza di base
add_header Referrer-Policy "strict-origin-when-cross-origin";
add_header Content-Security-Policy "default-src 'self'; script-src 'self' 'unsafe-inline' 'unsafe-eval'; style-src 'self' 'unsafe-inline'; img-src 'self' data: https:; font-src 'self' data:; connect-src 'self' http://host.docker.internal:4123 ws://localhost:*";
server_tokens off;
client_max_body_size 10M;
}
Se preferisci 127.0.0.1, cambia
set $api http://127.0.0.1:4123;.
Nel nginx.conf metti:
set $api http://chatterbox-tts:4123;perché i servizi condividono la rete Compose.
⚠️ In PowerShell usa
curl.exe(non l’aliascurl) per evitare i classici errori di parametri.
curl.exe -s http://127.0.0.1:4123/languages
curl.exe -s http://127.0.0.1:4123/voicesFile di esempio: C:\Users\Francesco\Desktop\tts\italian_sample.wav (16 kHz/24 kHz, mono, 5–20 s, pulito).
curl.exe -s -X POST http://127.0.0.1:4123/voices `
--form "voice_name=italian_sample" `
--form "language=it" `
--form "voice_file=@C:\Users\Francesco\Desktop\tts\italian_sample.wav"Verifica:
curl.exe -s http://127.0.0.1:4123/voicescurl.exe -s -X POST http://127.0.0.1:4123/audio/speech `
--json "{`"input`": `"Ciao, come stai? Tutto bene?`", `"voice`": `"italian_sample`", `"language_id`": `"it`", `"exaggeration`": 0.4, `"cfg_weight`": 0.3, `"temperature`": 0.6}" `
--output out.wavApri out.wav e ascolta.
import requests
URL = "http://127.0.0.1:4123/audio/speech/stream"
payload = {
"input": "Ciao! Prova di streaming in tempo reale.",
"voice": "italian_sample",
"language_id": "it",
"streaming_strategy": "sentence",
"exaggeration": 0.4,
"cfg_weight": 0.3,
"temperature": 0.6
}
with requests.post(URL, json=payload, stream=True, timeout=120) as r:
r.raise_for_status()
with open("stream.wav", "wb") as f:
for chunk in r.iter_content(8192):
if chunk:
f.write(chunk)
print("OK -> stream.wav")language_id: “it”cfg_weight (Pace): 0.3–0.45exaggeration (Emozione): 0.35–0.6temperature (creatività): 0.55–0.8cfg_weight ~0.35).curl.exe -s -X POST http://127.0.0.1:4123/voices/default -d "voice_name=italian_sample" curl.exe -s http://127.0.0.1:4123/voices/defaultcurl.exe -s "http://127.0.0.1:4123/memory?cleanup=true&force_cuda_clear=true"curl.exe -s http://127.0.0.1:4123/status curl.exe -s http://127.0.0.1:4123/status/statistics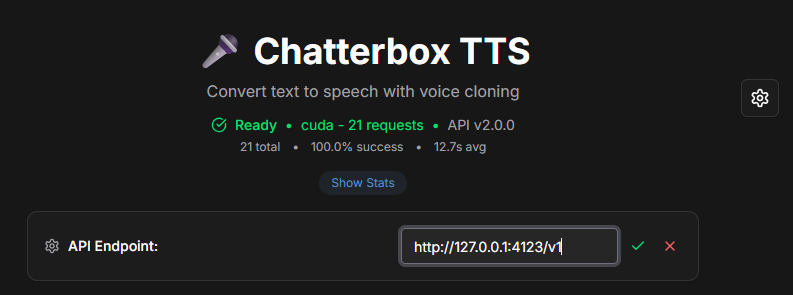
-e VITE_API_BASE=http://host.docker.internal:4123 oppure modifica nginx.conf come in §5.1.host.docker.internal (Windows/Mac) o 127.0.0.1.curl che “non capisce” -H o -dcurl è Invoke-WebRequest. Usa curl.exe.docker compose -f docker-compose.cpu.yml downDevice: cuda) e docker exec ... nvidia-smi. Abilita GPU in Docker Desktop.http://127.0.0.1:4123 per i test curl.Spegni i container:
# backend (CPU o GPU)
cd chatterbox-tts-api\docker
docker compose -f docker-compose.cpu.yml down
docker compose -f docker-compose.gpu.yml down
# frontend
docker rm -f tts-frontendRimuovi immagini (facoltativo):
docker rmi docker-chatterbox-tts chatterbox-tts-frontendVolumi (attenzione: perdi voci caricate e cache modelli):
docker volume rm docker_chatterbox-voices docker_chatterbox-modelsSalva come docker-compose.all.yml nella cartella docker/:
services:
chatterbox-tts:
build:
context: ..
dockerfile: docker/Dockerfile.cpu
image: docker-chatterbox-tts
ports:
- "4123:4123"
volumes:
- chatterbox-models:/cache
- chatterbox-voices:/voices
tts-frontend:
build:
context: ../frontend
image: chatterbox-tts-frontend
ports:
- "8080:80"
environment:
- VITE_API_BASE=http://chatterbox-tts:4123
depends_on:
- chatterbox-tts
volumes:
chatterbox-models:
chatterbox-voices:Lancio:
cd chatterbox-tts-api\docker
docker compose -f docker-compose.all.yml up -d --build
start http://localhost:8080/docs o con script.docker-desktop; è normale (cache)..wslconfig se vuoi.In locale Chatterbox TTS è tra i motori più semplici da mettere in piedi e integrare via API. Per assistenti vocali, demo e POC è già usabile (soprattutto su GPU). In italiano resta un po’ di accento/prosodia da rifinire per voice-over pro. Continuerò i test e aggiornerò il post quando usciranno preset/modelli migliori.
Spero che questa guida ti sia stata utile, se hai dubbi e domande o semplicemente vuoi condividere il tuo feedback ti invito a scrivere un commento qui sotto.
Se leggi spesso i miei articoli su AI, automazione e tecnologia, ora puoi dire a Google che vuoi vedere più spesso i contenuti di francescogruner.it tra le notizie.