Ricevi la newsletter
Tool, prompt e workflow AI. Una volta a settimana, gratis.
Sei dentro. Da questa settimana ricevi la newsletter.
Claude Fable 5 non è solo un modello che risponde meglio: è pensato per lavorare su task lunghi, complessi e agentici. L’ho provato con Claude Code su una codebase reale, tra UI, layout, widget, migrazioni e refactor. Il risultato mostra una cosa chiara: questi modelli possono produrre molto lavoro, ma vanno gestiti con metodo, soprattutto quando entrano in gioco subagenti, contesto lungo e sessioni operative.

Non perché “risponde meglio” alle domande.
Quella ormai è la parte meno interessante.
Il punto vero è un altro: Claude Fable 5 sembra progettato per lavorare su task lunghi, complessi e agentici, cioè attività in cui il modello non deve solo generare testo, ma deve osservare, ragionare, usare strumenti, modificare codice, verificare risultati e portare avanti un lavoro tecnico reale.
Io l’ho provato con Claude Code su una codebase vera.
Non una demo da conferenza.
Non il solito progettino “fammi una landing page moderna”.
Non un test costruito per fare bella figura.
Una sessione reale, lunga, sporca, con problemi di UI, layout, widget, migrazioni, refactor e controlli da fare.
Il risultato è stato molto interessante.
Ma mi ha anche fatto capire una cosa importante: quando questi modelli vengono usati come agenti operativi, la potenza va gestita con metodo.
Perché Fable 5 può produrre molto lavoro.
Ma se lo usi in sessioni lunghe, con tanto contesto e molti subagenti, può diventare anche molto costoso.
In pratica, ci stiamo spostando da:
prompt → risposta
a:
obiettivo → piano → azione → verifica → correzione → risultato
Ed è un passaggio importante.
Perché quando l’AI non si limita più a suggerire, ma inizia a lavorare dentro un ambiente, cambiano anche le responsabilità di chi la usa.
Claude Fable 5 è uno dei nuovi modelli di Anthropic pensati per portare le capacità della famiglia Mythos a un pubblico più ampio.
Anthropic lo presenta come un modello adatto a progetti ambiziosi e di lunga durata, soprattutto quando viene usato dentro ambienti agentici come Claude Code o altri sistemi in grado di far usare strumenti, file, terminale e subagenti.
Questa è la differenza principale rispetto alla classica esperienza da chatbot.
Fable 5 non nasce solo per rispondere bene a una domanda.
Nasce per lavorare su attività più lunghe:
→ analizzare una codebase
→ pianificare più passaggi
→ usare strumenti
→ delegare sotto-attività
→ controllare il proprio lavoro
→ correggere errori
→ iterare fino a un risultato
È la stessa direzione che avevo già raccontato parlando di Claude Opus 4.8 e dei workflow dinamici in Claude Code: l’AI non è più solo un assistente che suggerisce codice, ma inizia a comportarsi come un ambiente operativo.
E questo cambia parecchio le regole del gioco.
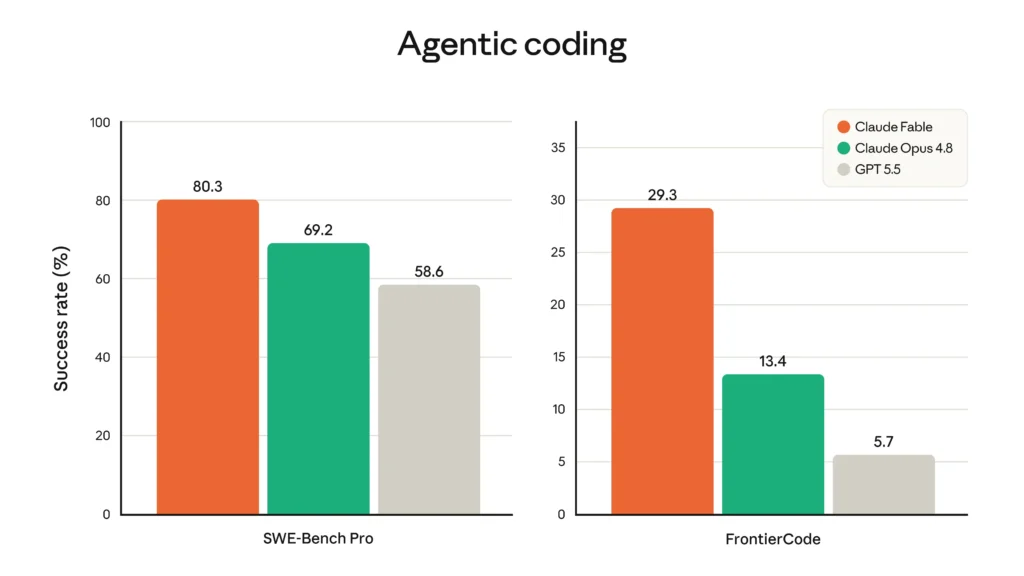
Nei benchmark pubblicati da Anthropic, Fable 5 mostra risultati molto forti soprattutto nel coding agentico.
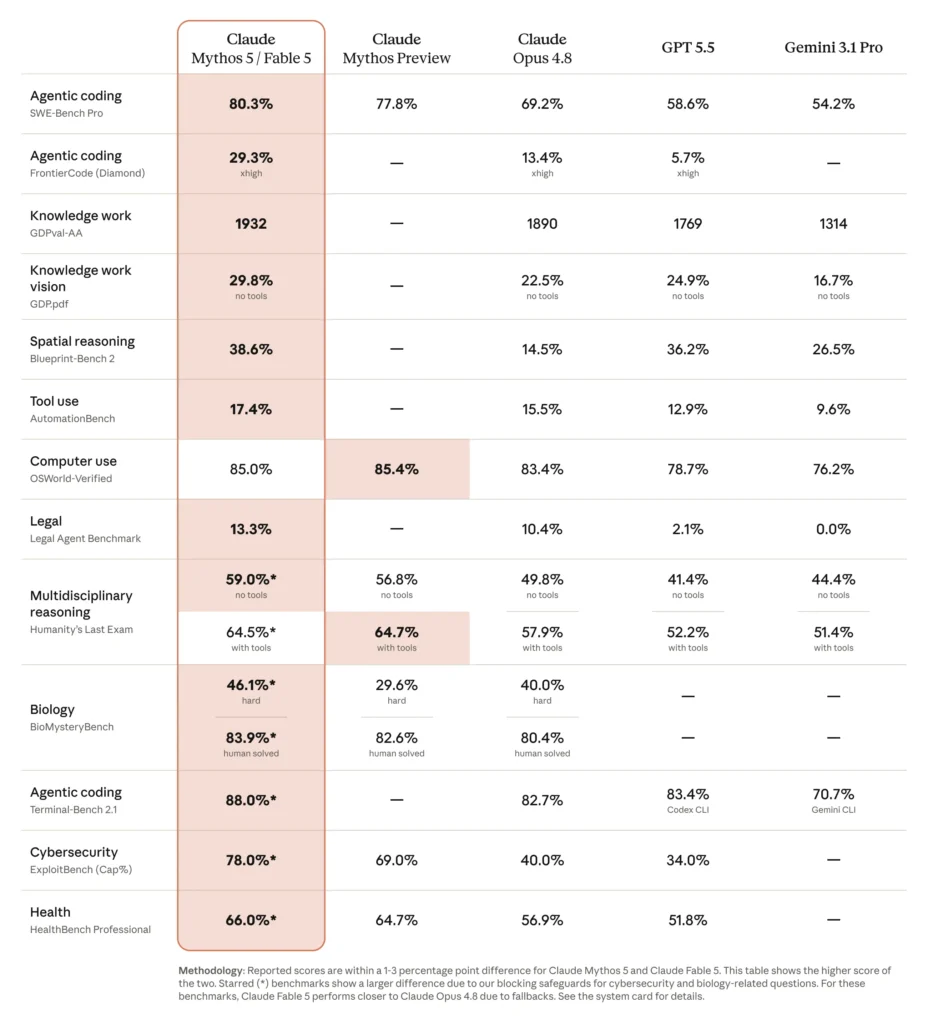
Su SWE-Bench Pro, Fable 5 arriva all’80,3%, superando Claude Opus 4.8, GPT-5.5 e Gemini 3.1 Pro.
Su FrontierCode, un benchmark più duro e orientato ai task di sviluppo agentico, Fable 5 raggiunge il 29,3%, contro il 13,4% di Claude Opus 4.8 e il 5,7% di GPT-5.5.
Questi numeri non vanno letti come una verità assoluta.
I benchmark sono utili, ma non raccontano tutto.
La parte interessante è la direzione: Fable 5 non sembra pensato per piccoli prompt veloci, ma per task lunghi, complessi e ad alto effort.
E questo si vede ancora meglio nel rapporto tra prestazioni e costo.
Ricevi una guida pratica ogni settimana. AI, tool e automazioni.
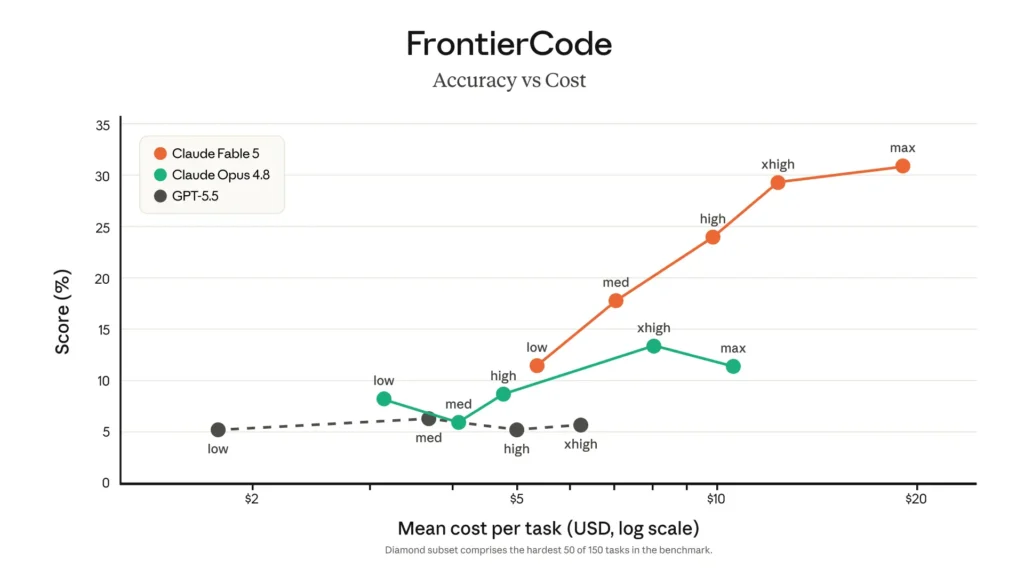
Questa immagine è forse la più importante.
Perché mostra una cosa semplice: i modelli agentici più potenti possono produrre più valore, ma richiedono anche più attenzione nella gestione dei costi.
Quando lavori con un modello come Fable 5, il costo non dipende solo dal prompt iniziale.
Dipende da tutto il processo:
→ quanto contesto deve leggere
→ quanti file analizza
→ quanti strumenti usa
→ quanti subagenti vengono avviati
→ quanto output genera
→ quante iterazioni fa
→ quanto dura la sessione
→ quanto spesso viene riutilizzato contesto tramite cache
Questo è il cambio mentale.
Non stai pagando una risposta.
Stai pagando una sessione operativa.
E se il task è importante, può avere senso.
Ma se il task è banale, rischia di diventare solo un modo molto elegante per bruciare budget.
La parola chiave qui è agentico.
Un modello agentico non si limita a generare una risposta.
Deve tenere insieme più passaggi:
→ capire l’obiettivo
→ esplorare il contesto
→ scegliere una strategia
→ modificare file
→ verificare errori
→ correggere
→ riprovare
È molto diverso dal classico uso di ChatGPT o Claude per scrivere una funzione isolata.
Nel coding reale, il problema non è quasi mai “scrivere codice”.
Il problema è capire dove intervenire, cosa non rompere, come mantenere coerenza e come verificare che la modifica abbia davvero funzionato.
È qui che modelli come Fable 5 diventano interessanti.
Ho usato Claude Fable 5 dentro Claude Code su una codebase reale.
Non lo considero un benchmark scientifico.
Lo considero una prova sul campo utile per capire cosa succede quando si usa un modello agentico potente in una sessione lunga, con molti strumenti e molto contesto.
Il report finale della sessione mostrava questi dati:
Total cost: $525.45 Total duration API: 7h 31m 49s Total duration wall: 2d 0h 28m Total code changes: 21.218 lines added, 4.906 lines removed
In pratica:
→ 525,45 dollari di costo totale
→ 7 ore e 31 minuti di tempo API effettivo
→ circa 2 giorni di sessione reale aperta
→ 21.218 righe aggiunte
→ 4.906 righe rimosse
→ oltre 26.000 righe di codice toccate
Il dato può sembrare forte, ma va letto bene.
Non significa che “Fable 5 costa sempre così”.
Significa che, in una sessione lunga e pesante, con molti subagenti e tanto contesto, i costi possono crescere rapidamente.
Il dettaglio più importante del report era questo:
100% of your usage came from subagent-heavy sessions
47% of your usage was at >150k context
33% of your usage came from subagents under "general-purpose"Questo cambia completamente la lettura.
Il costo non dipendeva solo da Fable 5.
Dipendeva da come era strutturata la sessione:
→ molti subagenti
→ contesto sopra i 150.000 token
→ sessione lunga
→ tanto output
→ uso pesante della cache
→ Fable 5 usato per quasi tutto
Quindi la lezione non è:
“Fable 5 costa troppo.”
La lezione è:
“Fable 5 va usato con metodo, soprattutto quando lo trasformi in un agente operativo.”
Guardando i numeri, si potrebbe pensare che il problema sia stato la cache.
Secondo me no.
La cache non è il nemico.
Anzi, probabilmente ha evitato costi ancora più alti, perché ha permesso di riutilizzare molto contesto già processato.
Nel mio caso il report mostrava:
→ 247,8 milioni di token letti da cache
→ 12,8 milioni di token scritti in cache
→ 1,8 milioni di token di output
Sono numeri enormi.
Ma non li leggerei come “errore della cache”.
Li leggerei come il segnale di una sessione molto pesante.
Il problema nasce quando una sessione diventa lunga, il contesto cresce troppo, i subagenti si moltiplicano e non si separano bene i task.
In quel caso bisogna iniziare a gestire il contesto come una risorsa tecnica.
Come la RAM.
Come lo storage.
Come il budget cloud.
Se lo lasci crescere senza controllo, prima o poi paghi.
Letteralmente.
Le demo pubblicate da Anthropic aiutano a capire perché Fable 5 non è semplicemente “un modello per programmare”.
Una delle più curiose mostra Claude Fable 5 che completa Pokémon FireRed usando solo la visione.
La parte interessante non è il gioco.
La parte interessante è che il modello deve:
→ osservare
→ interpretare
→ ricordare
→ decidere
→ correggere
→ continuare per molto tempo
È un esempio di comportamento agentico in un ambiente visuale.
E si collega al tema più ampio del computer use, di cui ho parlato anche nell’articolo su GPT-5.4, agenti, tool search e computer-use.
Un’altra demo mostra Fable 5 mentre costruisce una simulazione del sistema solare e la usa per prevedere eclissi.
Qui il punto non è solo il risultato finale.
Il punto è il processo:
→ ragionamento fisico
→ codice
→ simulazione
→ visualizzazione
→ verifica
→ iterazione
I modelli non stanno diventando solo più bravi a scrivere testo o codice.
Stanno diventando più bravi a costruire sistemi, testarli e usarli.
Ed è una differenza enorme.
La demo su VibeCAD è forse la più interessante per chi lavora su prodotti digitali.
Fable 5 progetta un modello 3D stampabile dentro un editor CAD nel browser. Ma la parte davvero interessante è che anche l’editor, incluso il copilota AI integrato, è stato creato da Fable 5.
Questo è un passaggio importante.
Non parliamo più solo di AI che produce un output.
Parliamo di AI che può:
→ costruire uno strumento
→ usare quello strumento
→ migliorarlo
→ produrre nuovi risultati attraverso quello strumento
Prima chiedevamo all’AI di scrivere una funzione.
Poi le abbiamo chiesto di creare un’app.
Ora iniziamo a chiederle di creare ambienti, interfacce e workflow che permettono di produrre altre cose.
È lo stesso territorio del vibe coding, tema che ho approfondito nella guida ai tool AI, local e CLI per sviluppare in sintonia.
Secondo me Fable 5 ha senso quando il task è abbastanza complesso da giustificare costo e attenzione.
Lo userei per:
→ refactor importanti
→ analisi di codebase complesse
→ debug difficili
→ migrazioni
→ sviluppo di feature articolate
→ sistemazione profonda di UI e componenti
→ workflow multi-step
→ revisione tecnica ampia
Non lo userei invece per:
→ piccole modifiche CSS
→ snippet semplici
→ micro-task da pochi minuti
→ cambi testuali banali
→ richieste senza contesto chiaro
→ sessioni lunghe senza obiettivo preciso
Fable 5 non è il modello da usare per tutto.
È uno strumento potente.
E proprio perché è potente, va usato con criterio.
La lezione principale del mio test è semplice: i modelli agentici vanno gestiti come processi, non come chat.
La prossima volta imposterei una sessione Fable 5 così.
Prima preparerei un brief tecnico con:
→ obiettivo preciso
→ file o aree coinvolte
→ vincoli
→ cosa non deve essere modificato
→ criteri di accettazione
→ limite massimo di costo
→ quando usare subagenti
→ quando usare modelli più economici
Durante la sessione controllerei:
→ costo
→ dimensione del contesto
→ uso dei subagenti
→ file modificati
→ necessità di fare compact
→ coerenza delle modifiche
A ogni cambio di task farei:
→ riepilogo tecnico
→ lista file modificati
→ stato del lavoro
→ eventuale nuova sessione pulita
Meno improvvisazione.
Più metodo.
Lo so, sembra meno romantico.
Ma quando un modello può consumare centinaia di dollari in poche ore, un po’ di metodo diventa improvvisamente molto poetico.
Fable 5 non va letto come “il modello che sostituisce gli sviluppatori”.
Questa è la lettura più banale.
La lettura più utile è un’altra:
Fable 5 aumenta la leva operativa di chi sa già cosa sta facendo.
Se hai esperienza, metodo e capacità di review, può aiutarti ad accelerare molto.
Se lo usi senza controllo, può solo aiutarti a creare confusione più velocemente.
Il valore dello sviluppatore si sposta sempre più da:
scrivere ogni singola riga di codice
a:
definire bene il lavoro, guidare l’agente, controllare l’output e validare il risultato.
Per le aziende il tema diventa ancora più serio.
Se un agente può leggere e modificare codice, servono regole:
→ chi può usarlo
→ su quali repository
→ con quali permessi
→ con quali dati
→ con quali limiti di spesa
→ con quali procedure di review
→ con quale tracciabilità
Qui non parliamo più del dipendente che usa ChatGPT per scrivere una mail.
Parliamo di agenti che possono operare su asset tecnici reali.
È un tema IT, non solo un tema AI.
Ed è anche il motivo per cui stanno diventando importanti framework, policy e architetture per agenti, come raccontavo nella guida sui documenti ufficiali Google sugli AI Agents.
Claude Fable 5 è uno dei segnali più chiari di dove sta andando l’AI applicata allo sviluppo software e al lavoro digitale.
Meno prompt isolati.
Più agenti.
Meno risposte singole.
Più workflow lunghi.
Meno “scrivimi questa funzione”.
Più “porta avanti questa parte di progetto”.
La cosa interessante non è solo la potenza del modello.
È il cambio di paradigma.
Fable 5 può lavorare su task lunghi, usare strumenti, delegare sub-attività, ragionare su contesto ampio e produrre molto lavoro.
Ma proprio per questo va usato con metodo.
Il mio test lo ha mostrato bene: una sessione lunga, subagent-heavy e con contesto enorme può diventare molto costosa.
Non perché la cache sia “sbagliata”.
Non perché Fable 5 sia “da evitare”.
Ma perché questi strumenti non sono più semplici chatbot.
Sono ambienti operativi.
E gli ambienti operativi vanno governati.
La conclusione, per me, è questa:
Fable 5 non è economico, ma può essere conveniente.
Sono due cose diverse.
Economico significa che costa poco.
Conveniente significa che produce più valore di quanto costa.
E con i modelli agentici questa distinzione diventa fondamentale.
L’AI non elimina il bisogno di competenza.
Lo amplifica.
Nel bene e nel male.
No. Claude Fable 5 è interessante soprattutto nei task agentici, cioè attività lunghe in cui il modello deve pianificare, usare strumenti, modificare file, verificare risultati e correggere errori. Il codice è uno degli ambiti più evidenti, ma non l’unico.
Il costo non dipende solo dal modello, ma da come è stata strutturata la sessione. Nel test sono entrati in gioco molti subagenti, contesto molto ampio, tante iterazioni, cache e una sessione lunga. In questi casi non stai pagando una singola risposta, ma un vero processo operativo.
No. La cache non va vista automaticamente come un errore. In una sessione lunga può aiutare a riutilizzare contesto già elaborato. Il problema nasce quando contesto, subagenti e durata della sessione crescono senza controllo.
Ha senso usarlo per task abbastanza complessi da giustificare costo e attenzione: refactor importanti, analisi di codebase, debug difficili, migrazioni, feature articolate, revisione tecnica ampia e workflow multi-step.
Non è ideale per micro-task, piccole modifiche CSS, snippet semplici, cambi testuali banali o richieste senza contesto chiaro. Per attività brevi può essere più sensato usare modelli più economici o sessioni molto più controllate.
No. La lettura più utile è che aumenta la leva operativa di chi sa già cosa sta facendo. Lo sviluppatore diventa ancora più importante nella definizione del lavoro, nella guida dell’agente, nella revisione e nella validazione del risultato.
La lezione principale è che i modelli agentici vanno gestiti come processi, non come semplici chat. Servono brief chiari, limiti di costo, controllo del contesto, gestione dei subagenti e verifiche regolari.
Per la stesura dell’articolo sono state consultate fonti ufficiali Anthropic relative a Claude Fable 5, Claude Code, pricing API, gestione dei costi, monitoraggio e prompt caching.
Annuncio ufficiale di Anthropic sui nuovi modelli Claude Fable 5 e Claude Mythos 5, con contesto su capacità, posizionamento e miglioramenti rispetto alle generazioni precedenti.
Apri fontePagina ufficiale del modello Claude Fable 5, utile per contestualizzare l’uso su progetti di coding complessi, migrazioni, implementazioni articolate e sessioni agentiche di lunga durata.
Apri fonteDocumentazione ufficiale Anthropic dedicata all’introduzione di Claude Fable 5 e Claude Mythos 5, con dettagli tecnici sul posizionamento dei modelli e sugli scenari d’uso consigliati.
Apri fontePanoramica ufficiale dei modelli Claude, incluse disponibilità, identificativi modello, piattaforme supportate e differenze tra Claude Fable 5, Mythos 5 e gli altri modelli Anthropic.
Apri fontePagina ufficiale dei prezzi API Anthropic, utile per collegare il test reale ai costi per milione di token, ai token di input/output e al peso economico delle sessioni lunghe.
Apri fonteDocumentazione ufficiale di Claude Code, l’ambiente agentico da terminale usato per lavorare su codebase reali, eseguire comandi, modificare file e gestire workflow di sviluppo.
Apri fonteGuida ufficiale alla gestione dei costi in Claude Code: uso del comando /usage, controllo del contesto, scelta del modello, riduzione dei token, subagenti e gestione dei costi nei team.
Apri fonteDocumentazione sul monitoraggio di Claude Code tramite OpenTelemetry, utile per tracciare costi, uso degli strumenti, metriche operative e attività degli agenti in ambienti aziendali.
Apri fonteGuida ufficiale al prompt caching, utile per spiegare come la cache possa ridurre costi e latenza nelle attività ripetitive o nei workflow con contesto stabile.
Apri fonteRiferimento ufficiale sui limiti API, spend limits, rate limits e uso della cache, utile per contestualizzare sessioni lunghe, consumo token e gestione operativa dei costi.
Apri fonteSe leggi spesso i miei articoli su AI, automazione e tecnologia, ora puoi dire a Google che vuoi vedere più spesso i contenuti di francescogruner.it tra le notizie.