Ricevi la newsletter
Tool, prompt e workflow AI. Una volta a settimana, gratis.
Sei dentro. Da questa settimana ricevi la newsletter.
GPT-5.5 è uscito il 23 aprile 2026: OpenAI presenta il suo modello più avanzato per coding, ricerca scientifica e lavoro quotidiano. Benchmark, prezzi API e cosa cambia davvero rispetto a GPT-5.4 e Claude Opus 4.7.

Questa settimana nel mondo AI è successo di tutto.
Anthropic ha rilasciato Claude Opus 4.7 e Claude Design. MiniMax ha lanciato il suo 2.7. OpenAI ha aggiornato GPT Image 2.0. E ieri, 23 aprile, è arrivato GPT-5.5.
Cinque annunci rilevanti in pochi giorni. Non è normale nemmeno per questo settore.
Ma c’è una cosa che i comunicati ufficiali non dicono. GPT-5.5 non è la risposta di OpenAI a Claude Opus 4.7, il modello che Anthropic ha appena reso disponibile al pubblico. È la risposta a Claude Mythos, il modello enterprise di Anthropic che la maggior parte degli utenti non ha ancora visto. Quello che circola internamente, che OpenAI conosce bene, e contro cui evidentemente si è misurata durante lo sviluppo.
Questo cambia la lettura dei benchmark. Quando vedi GPT-5.5 confrontato con Opus 4.7 e lo stacca su quasi tutto, non stai guardando il vero confronto. Stai guardando la versione pubblica di una gara che si gioca su un altro livello.
Detto questo, GPT-5.5 è comunque un salto reale. Vale la pena capire cosa cambia davvero per chi ci lavora ogni giorno.
Ah, mentre scrivo questo articolo è già uscito DeepSeek V4. Ci tornerò a breve con un pezzo dedicato!
OpenAI parla di AI agentica da mesi. Con GPT-5.5 si vede finalmente cosa intende in concreto. Il modello non elabora un prompt e restituisce un risultato. Capisce cosa stai cercando di fare, pianifica i passaggi, usa gli strumenti, verifica il risultato e va avanti anche quando il compito è incompleto o ambiguo.
La differenza si sente soprattutto nei task lunghi. Quelli in cui i modelli precedenti si fermavano a metà, chiedevano conferma o si perdevano nel contesto. GPT-5.5 rimane sul compito più a lungo e con più coerenza.
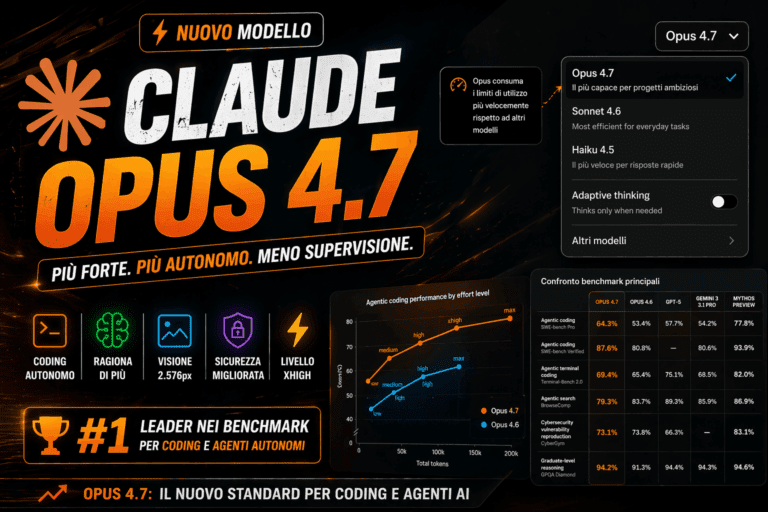
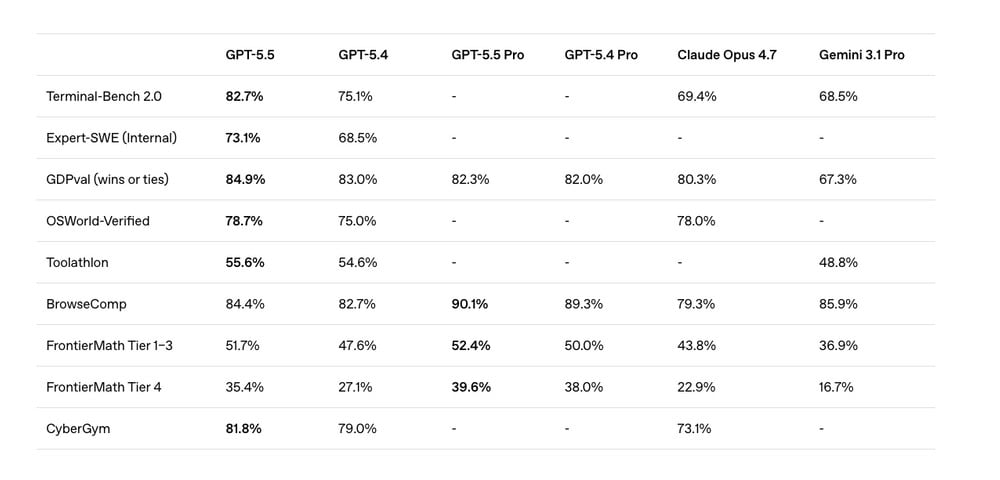
Su Terminal-Bench 2.0, il benchmark che misura flussi di lavoro complessi da riga di comando, ha raggiunto l’82,7%. Claude Opus 4.7 si ferma al 69,4%, GPT-5.4 al 75,1%.
La parte più interessante dei feedback raccolti durante l’accesso anticipato non riguarda i numeri. Riguarda il modo in cui il modello capisce la struttura di un sistema.
Prendo un esempio concreto. Dan Shipper, CEO di Every, aveva un bug che lui e il suo team migliore non riuscivano a risolvere da giorni. Alla fine avevano deciso di riscrivere parte del sistema. Ha poi usato GPT-5.5 per testarlo: partendo dallo stato rotto del codice, il modello ha prodotto esattamente la stessa riscrittura che l’ingegnere senior aveva deciso di fare. GPT-5.4 non c’era riuscito. GPT-5.5 sì.
Non è solo il file su cui stai lavorando. È l’intera architettura. Il motivo per cui qualcosa sta fallendo. Dove deve atterrare la correzione. Cosa nel resto del codice viene toccato da quella modifica.
Pietro Schirano di MagicPath ha testato GPT-5.5 su un merge con centinaia di modifiche frontend: il modello ha risolto tutto in un colpo solo, in circa 20 minuti. Michael Truell di Cursor ha detto che rimane sul task significativamente più a lungo senza fermarsi prima del previsto, che è esattamente il problema che rende inutilizzabile un agente di coding su lavori complessi.
Un ingegnere NVIDIA è stato più diretto: perdere l’accesso a GPT-5.5 è come avere un arto amputato. Iperbolico, certo. Ma racconta bene il salto percepito.
Ricevi una guida pratica ogni settimana. AI, tool e automazioni.
Le stesse capacità si estendono al lavoro quotidiano su computer. GPT-5.5 può gestire fogli di calcolo, documenti, presentazioni e flussi di lavoro aziendali muovendosi tra applicazioni diverse con una precisione che i modelli precedenti non avevano.
OpenAI ha condiviso qualche esempio interno. Il team Finance ha usato il modello per esaminare 24.771 moduli fiscali K-1, oltre 71.000 pagine, completando il lavoro con due settimane di anticipo rispetto all’anno precedente. Il team Communications ha costruito un agente Slack per gestire automaticamente le richieste di intervento pubblico a basso rischio, lasciando all’uomo solo quelle più delicate.
Su GDPval, il benchmark che testa agenti su 44 occupazioni diverse, GPT-5.5 raggiunge l’84,9%. Claude Opus 4.7 si ferma all’80,3%, Gemini 3.1 Pro al 67,3%.
Una versione interna di GPT-5.5, con un harness dedicato, ha contribuito a trovare una nuova dimostrazione matematica sui numeri di Ramsey, un problema aperto in combinatoria. Il risultato è stato poi verificato formalmente in Lean.
Non è un esercizio accademico. È un contributo concreto a un’area di ricerca dove i progressi sono rari e tecnicamente difficili.
Su BixBench, un benchmark di bioinformatica su dati reali, il modello raggiunge l’80,5% contro il 74% di GPT-5.4. Un professore di immunologia del Jackson Laboratory ha usato GPT-5.5 Pro per analizzare un dataset con 62 campioni e quasi 28.000 geni, producendo un report che, secondo lui, avrebbe richiesto mesi al suo team.
Brandon White di Axiom Bio ha sintetizzato bene il punto: se OpenAI continua su questa strada, le basi della scoperta di farmaci cambieranno entro la fine dell’anno. Può sembrare eccessivo, ma il pattern è coerente su tutti i benchmark scientifici testati.
GPT-5.5 è stato co-progettato e addestrato su sistemi NVIDIA GB200 e GB300 NVL72. Il risultato pratico è che mantiene la stessa latenza di GPT-5.4, pur essendo significativamente più capace.
Ancora più importante: usa meno token per completare gli stessi task. OpenAI dice che un’ottimizzazione del bilanciamento del carico GPU, sviluppata proprio con l’aiuto di Codex, ha aumentato la velocità di generazione dei token di oltre il 20%.
Per chi usa il modello via API questo conta. Il prezzo per token è più alto, ma se il modello finisce il lavoro con meno token, il costo finale può essere comparabile o inferiore rispetto a GPT-5.4. Da verificare caso per caso, ma la direzione è quella giusta.
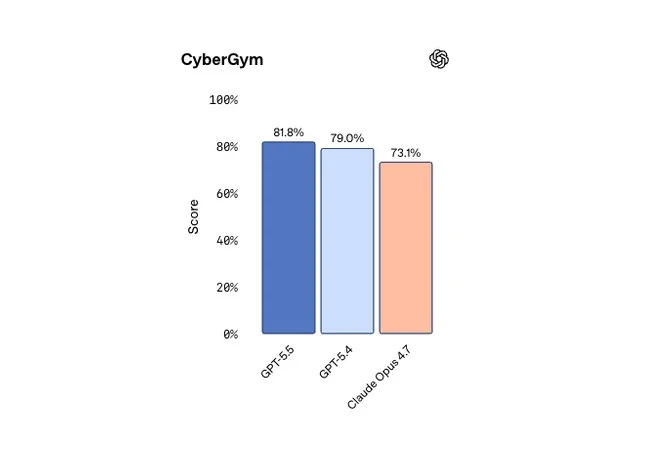
Le capacità avanzate in cybersecurity e biologia sono state classificate a livello “High” nel framework interno di OpenAI. Non si è raggiunto il livello “Critical”, ma rispetto a GPT-5.4 il modello è più capace in entrambi gli ambiti.
La conseguenza pratica: filtri più stretti su richieste legate alla sicurezza informatica. OpenAI riconosce esplicitamente che alcuni utenti troveranno inizialmente più rifiuti, anche su richieste legittime. I filtri verranno calibrati nel tempo.
Per chi fa lavoro difensivo verificato su infrastrutture critiche, esiste un programma di Trusted Access dedicato.
→ openai.com/cyber per candidarsi
GPT-5.5 è in distribuzione progressiva per gli utenti Plus, Pro, Business ed Enterprise su ChatGPT e Codex. GPT-5.5 Pro, la variante per i task più pesanti, è riservata ai piani Pro, Business ed Enterprise.
L’API arriva “a breve” con prezzi di 5 dollari per milione di token in input e 30 in output. Il doppio rispetto a GPT-5.4.
Sui forum e su Reddit la community si è divisa in modo prevedibile. Chi lavora nel coding racconta esperienze vicine alla magia: bug irrisolvibili sistemati al primo tentativo, refactoring complessi portati a termine in autonomia. Chi usa il modello per writing e analisi più semplice vede meno differenza e guarda con sospetto a un aumento di prezzo che non percepisce nei risultati.
C’è anche chi ha notato una cosa scomoda: su SWE-Bench Pro, uno dei benchmark chiave per il coding, Claude Opus 4.7 ottiene il 64,3% contro il 58,6% di GPT-5.5. OpenAI ha inserito una nota tecnica al riguardo, ma il dato non compare nel confronto principale della pagina. Non è passato inosservato.
La frustrazione più diffusa riguarda però l’assenza dell’API dal giorno uno. Un generico “a breve” non basta a chi ha prodotti in produzione e vuole testare prima di migrare.
Dipende da cosa fai.
Se lavori su codebase complesse, gestisci task lunghi o fai ricerca su dataset articolati, il salto rispetto a GPT-5.4 è reale e documentato. I feedback degli early tester sono tra i più entusiasti visti per un aggiornamento OpenAI negli ultimi mesi.
Se usi il modello principalmente per writing o compiti che si esauriscono in un singolo prompt, il miglioramento è più sottile. L’aggiornamento è pensato per chi lavora su più passaggi, non per chi fa domande singole.
Per l’API, ha senso aspettare qualche settimana di test su casi d’uso reali prima di aggiornare i flussi di lavoro. La questione dei token è più complessa di quanto sembri a prima vista e ogni caso è diverso.
Nel frattempo, come dicevo all’inizio, è già uscito DeepSeek V4. Un modello da 1.600 miliardi di parametri con una finestra di contesto da un milione di token. Ci torno a breve.
Fonti e approfondimenti
Tutte le informazioni e i benchmark citati in questo articolo sono tratti dall’annuncio ufficiale di OpenAI e dalla system card di GPT-5.5, pubblicati il 23 aprile 2026.
I dati sui benchmark di efficienza e costo tra modelli sono consultabili su Artificial Analysis, che aggiorna periodicamente il confronto tra i principali modelli frontier.
Il punteggio su Terminal-Bench 2.0 (82,7%) e quello su BixBench (80,5%) sono stati misurati direttamente da OpenAI e riportati nell’annuncio. Per i dettagli sulla ricerca in genetica, OpenAI ha pubblicato una pagina dedicata a GeneBench.
La dimostrazione sui numeri di Ramsey, verificata formalmente in Lean, è descritta in un post separato sul sito di OpenAI.
Per chi vuole candidarsi al programma di accesso verificato per la cybersecurity difensiva: openai.com/cyber.
Il teaser finale su DeepSeek V4 è basato sull’annuncio ufficiale pubblicato il 24 aprile 2026.
Se leggi spesso i miei articoli su AI, automazione e tecnologia, ora puoi dire a Google che vuoi vedere più spesso i contenuti di francescogruner.it tra le notizie.