
Ricevi la newsletter
Tool, prompt e workflow AI. Una volta a settimana, gratis.
Sei dentro. Da questa settimana ricevi la newsletter.
Claude Opus 4.7 è disponibile su Claude, API e cloud: migliora coding, task lunghi, document reasoning e computer use. Ma il punto vero è un altro: è il modello avanzato che Anthropic ha deciso di rendere pubblico.

Anthropic ha appena rilasciato Claude Opus 4.7.
E la notizia, per una volta, non è solo che “c’è un nuovo modello”.
La parte interessante è un’altra: non è il modello più potente che Anthropic ha in casa. Quel posto spetta ancora a Claude Mythos Preview, che però resta chiuso, limitato e usato in contesti controllati.
Opus 4.7, invece, è quello che puoi usare davvero.
Ed è proprio per questo che il rilascio conta.
Perché segna un passaggio chiaro: non siamo più nella fase in cui vince semplicemente il modello più forte. Stiamo entrando in quella in cui conta di più quale modello puoi mettere in produzione, quanto puoi fidarti di lui e quanta supervisione riesci a togliere dal flusso di lavoro.
Se si legge bene come Anthropic presenta Opus 4.7, il pattern è evidente.
Non spingono solo sulla potenza grezza. Spingono soprattutto su tre idee:
gestisce task lunghi con più rigore,
segue le istruzioni in modo più preciso,
verifica i propri output prima di rispondere.
Detta in modo più semplice: non stanno vendendo solo un modello che “risponde meglio”. Stanno cercando di vendere un modello a cui puoi delegare meglio.
Ed è una differenza enorme.
Fino a poco fa il flusso standard era questo:
prompt → output → correzione → nuovo prompt → altra correzione
Con Opus 4.7 Anthropic sta dicendo che il flusso può iniziare a diventare:
task → esecuzione → autocontrollo → risultato finale
Meno babysitting. Meno botta e risposta. Più fiducia nell’esecuzione.
Se mantiene questa promessa anche fuori dai benchmark, allora il salto non è cosmetico. È operativo.
Qui c’è un aspetto che secondo me merita attenzione, anche perché racconta bene dove sta andando il settore.
Anthropic dice apertamente che Opus 4.7 è meno capace di Mythos Preview. Soprattutto sul fronte cyber. E non è un limite casuale: è una scelta deliberata.
In pratica il messaggio è questo:
i modelli più forti esistono già,
ma non sono ancora quelli che vogliono lasciare nelle mani di tutti.
Opus 4.7 nasce esattamente in questo spazio intermedio. È il modello avanzato, pubblico, con capacità forti ma con paletti più stretti. In particolare sul fronte cybersecurity, dove Anthropic ha spiegato di aver persino provato a ridurre in modo differenziale alcune capacità durante l’addestramento, oltre ad aver inserito safeguard che bloccano richieste ad alto rischio.
Per chi si occupa di AI in azienda questo è un segnale molto chiaro.
La competizione non è più solo su “chi ha il benchmark più alto”. È sempre più su chi riesce a distribuire modelli potenti senza perdere il controllo.
Ricevi una guida pratica ogni settimana. AI, tool e automazioni.
La parte più forte del rilascio è probabilmente il coding.
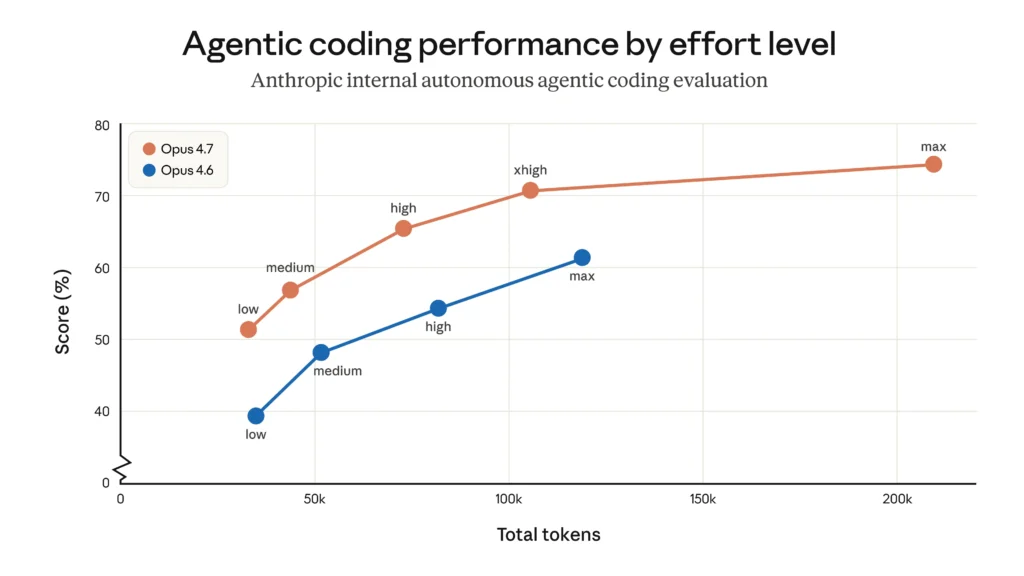
Anthropic lo dice chiaramente: Opus 4.7 migliora in modo evidente rispetto a Opus 4.6 sull’advanced software engineering, soprattutto nei task più difficili e lunghi. E i benchmark vanno nella stessa direzione.
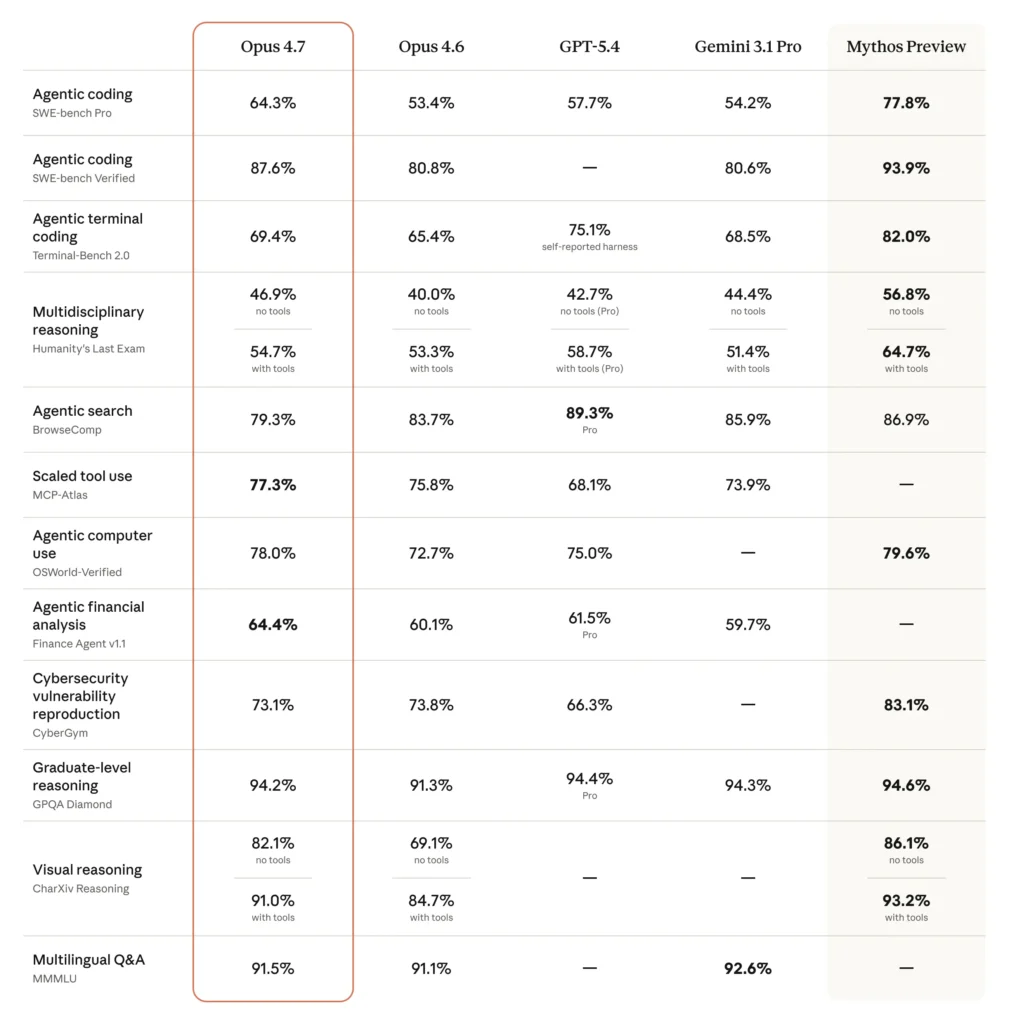
Su SWE-bench Pro passa da 53.4% a 64.3%.
Su SWE-bench Verified passa da 80.8% a 87.6%.
Non è un incremento marginale. È il tipo di miglioramento che inizia a cambiare il modo in cui usi il modello in un contesto reale, soprattutto se lavori su basi di codice grandi, task multi-step o flussi agentici dove il vero problema non è scrivere due righe di codice, ma non deragliare dopo il terzo, quarto o quinto passaggio.
Anche sul lato terminale il passo avanti si vede, anche se meno spettacolare: su TerminalBench 2.0 Opus 4.7 arriva a 69.4%, sopra Opus 4.6 e Gemini 3.1 Pro, ma ancora sotto GPT-5.4 in quel test specifico.
Ed è giusto dirlo, perché è qui che un articolo serio si distingue da un pezzo promozionale: Opus 4.7 non domina ovunque. Ma nelle aree in cui Anthropic ha deciso di spingere, il miglioramento è concreto.
Uno dei dati più interessanti, almeno per chi lavora in azienda, è poi il document reasoning.
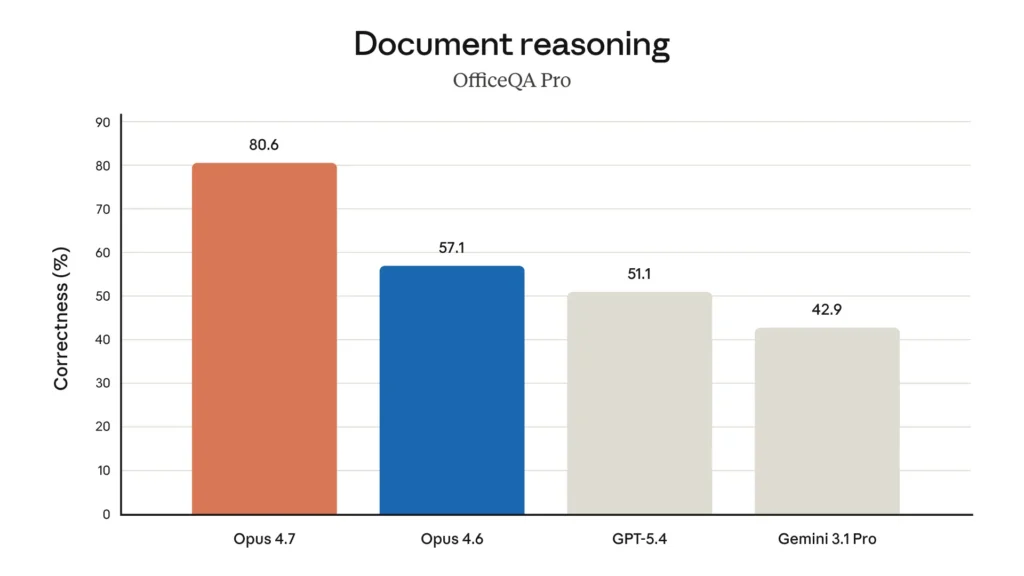
Su OfficeQA Pro, Opus 4.7 arriva a 80.6%, mentre Opus 4.6 si fermava a 57.1%. GPT-5.4 è a 51.1% e Gemini 3.1 Pro a 42.9%.
Questo dato è enorme, perché esce dalla nicchia “AI per sviluppatori” e tocca il lavoro vero di tantissimi team: documenti, analisi, presentazioni, materiali interni, procedure, report, file ibridi pieni di testo e struttura.
Se questo dato regge anche nell’uso reale, Opus 4.7 non è solo un modello da coding. È un modello da knowledge work serio.
Un altro miglioramento che rischia di passare in secondo piano, ma che in realtà pesa molto, è quello sulla visione.
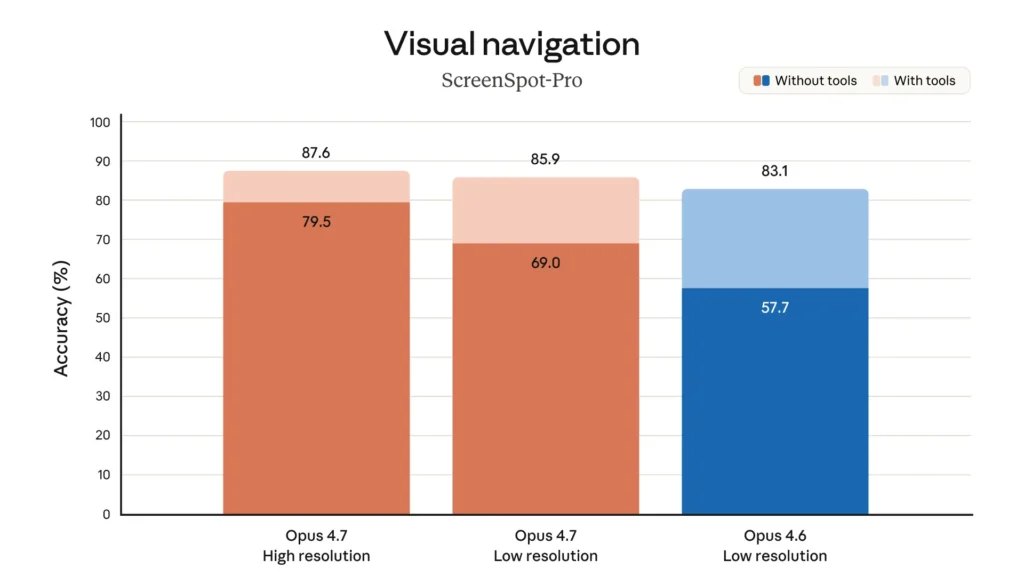
Opus 4.7 supporta immagini fino a 2.576 pixel sul lato lungo, cioè circa 3,75 megapixel, oltre tre volte rispetto ai Claude precedenti.
Detta così sembra solo una nota tecnica. In pratica cambia parecchio.
Vuol dire migliore lettura di screenshot densi, diagrammi tecnici, interfacce complesse, documenti con dettagli minuti, flussi visuali che richiedono riferimenti più precisi. E infatti alcuni benchmark lo riflettono: nei test su navigazione visuale e ragionamento documentale Opus 4.7 mostra un vantaggio piuttosto netto.
Questo si collega direttamente anche a tutto il filone computer use, che tra l’altro nel frattempo Anthropic ha esteso anche a Windows su Claude Desktop. Ed è proprio qui che il modello nuovo diventa interessante: non solo perché “vede meglio”, ma perché questa visione migliore può rendere più affidabili flussi agentici che lavorano davvero su schermate, UI e ambienti reali.
Un altro tassello interessante riguarda la memoria basata su file system.
Anthropic dice che Opus 4.7 usa meglio la memoria tra sessioni, ricorda note importanti e ha bisogno di meno contesto iniziale per portare avanti task successivi. Questo, combinato con una maggiore coerenza nei task lunghi, racconta un modello pensato meno per la chat occasionale e più per il lavoro continuativo.
È un punto importante perché, nella pratica, uno dei limiti più fastidiosi di molti modelli non è solo la qualità della risposta singola. È la difficoltà a restare allineati nel tempo. Appena il lavoro si allunga, il contesto si sporca, gli obiettivi slittano e il modello comincia a improvvisare.
Anthropic sta chiaramente cercando di ridurre proprio questo problema.
Guardando la tabella generale, Opus 4.7 migliora quasi ovunque rispetto a Opus 4.6. In alcuni casi supera GPT-5.4 e Gemini 3.1 Pro, in altri no. Mythos resta sopra in diverse aree, come previsto.
Ma secondo me il punto non è stilare una classifica da stadio.
La domanda giusta è: che tipo di modello stanno cercando di costruire?
E la risposta è abbastanza chiara: un modello premium, general availability, forte su coding, task agentici, documenti, visione e lavoro professionale, ma con limiti e controlli sufficienti per essere distribuito a più utenti.
In altre parole, non il modello più estremo. Il modello più spendibile.
Sulla carta il prezzo resta identico a Opus 4.6:
5 dollari per milione di token in input
25 dollari per milione di token in output
Buona notizia? Sì. Ma fino a un certo punto.
Perché Anthropic avverte anche che Opus 4.7 usa un tokenizer aggiornato, quindi a parità di input può consumare da 1.0 a 1.35 volte più token, a seconda del contenuto. E se lo fai ragionare con effort più alti, soprattutto nei task agentici, tende anche a produrre più output token.
Quindi il prezzo per token non cambia, ma il costo reale del workflow può cambiare eccome.
È una distinzione che tanti post celebrativi ignorano, ma per chi sviluppa prodotti o automazioni è fondamentale. Non basta sapere quanto costa il modello. Devi sapere quanto costa farlo lavorare davvero.
Tra le novità collaterali ci sono anche segnali interessanti sul prodotto.
Anthropic introduce il nuovo livello di effort xhigh, a metà tra high e max, per dare più controllo sul trade-off tra latenza e ragionamento. In Claude Code questo livello diventa addirittura il default per Opus 4.7.
Arriva anche /ultrareview, una sessione dedicata alla revisione del codice che promette di individuare bug e problemi di design da revisore attento. E per gli utenti Max si estende anche la modalità auto, cioè la possibilità per Claude di prendere più decisioni in autonomia sulle autorizzazioni durante task lunghi.
Tutto questo va nella stessa direzione: meno chat da usare come assistente passivo, più strumento da inserire in workflow continui e più autonomi.
Le reazioni che si vedono in giro sono abbastanza interessanti, e in parte prevedibili.
Da un lato c’è curiosità vera. Molti vedono Opus 4.7 come il primo modello Anthropic da testare seriamente su coding lungo, agenti e task di produzione. Dall’altro lato c’è già il solito scetticismo della community più smaliziata.
Alcuni utenti fanno notare che i miglioramenti sembrano più forti nei benchmark e nei test controllati che non in tutti gli scenari quotidiani. Altri criticano il maggior consumo di token, che può tradursi in limiti di piano percepiti come più stretti. Altri ancora sostengono che una parte del salto dipenda non solo dal modello, ma anche da come viene gestito il thinking o dai nuovi livelli di effort.
Sono osservazioni normali e, anzi, utili. Perché ci ricordano una cosa semplice: un modello non si giudica il giorno del rilascio. Si giudica dopo una o due settimane di uso reale, quando esce dai demo case e finisce dentro flussi sporchi, repo grandi, prompt imperfetti e task meno fotogenici.
Per questo, al netto dell’entusiasmo, Opus 4.7 va provato bene.
La ragione per cui Opus 4.7 è interessante non è solo tecnica. È strategica.
Anthropic ti sta dicendo che il futuro non sarà semplicemente “rilasciamo il modello più forte che abbiamo”. Sarà piuttosto:
rilasciamo il modello più forte che possiamo permetterci di distribuire.
E questo, per chi lavora tra sviluppo, automazione, consulenza AI, strumenti enterprise o workflow agentici, è probabilmente il segnale più importante di tutto il lancio.
Perché sposta la conversazione:
non più solo “quanto è bravo il modello?”
ma “quanto posso affidargli senza doverlo seguire passo passo?”
Ed è qui che Opus 4.7 si gioca la partita vera.
Io stavo già per fare un video sul nuovo aggiornamento di Claude Desktop, anche perché nel frattempo Anthropic ha portato il computer use anche su Windows.
Ma con Opus 4.7 il contesto diventa molto più interessante.
Perché adesso non c’è solo una nuova funzione da mostrare. C’è un modello nuovo che, almeno sulla carta, promette di rendere più credibile tutto il discorso su delega, agenti, esecuzione lunga e lavoro reale.
Se mantiene anche solo una buona parte di quello che promette, allora non siamo davanti all’ennesimo “point release”. Siamo davanti a un altro piccolo spostamento del baricentro: dalla chat al lavoro.
Claude Opus 4.7 non è il modello più potente di Anthropic.
È quello che Anthropic ha deciso di rendere pubblico.
E oggi, nel mondo dell’AI, questa differenza conta forse più del benchmark stesso.
Fonte: Anthropic
Se leggi spesso i miei articoli su AI, automazione e tecnologia, ora puoi dire a Google che vuoi vedere più spesso i contenuti di francescogruner.it tra le notizie.











