Ricevi la newsletter
Tool, prompt e workflow AI. Una volta a settimana, gratis.
Sei dentro. Da questa settimana ricevi la newsletter.
GPT-5.4 spinge su agenti, tool search e computer-use. Prezzi API, numeri e 3 prove secche → capisci in 5 minuti se ti serve davvero.

GPT-5.4 è il tipo di release che vedi meglio quando smetti di fare prompt e inizi a far lavorare il modello: documenti, fogli, strumenti, workflow lunghi. È lì che OpenAI sta spingendo: non “più brillante”, ma più utile e (nelle loro parole) più efficiente sui token.
Se ti interessa l’angolo pratico, questa è la lettura giusta: cosa cambia in ChatGPT, cosa cambia in API/Codex, quanto costa, e perché la parte “permessi e guardrail” non è più facoltativa.
→ In ChatGPT puoi correggere la rotta mentre sta rispondendo (piano upfront + reindirizzo in corsa).
→ In API/Codex entra nel mainline un modello che spinge su computer‑use, tool search e contesto fino a 1M token.
→ Se fai agenti: il risparmio non è “magico”. È meno token buttati in definizioni tool e contesto gonfio.
La cosa interessante non è che “ragiona di più”. È che, mentre produce, tu puoi fermarlo e dirgli: cambia formato, cambia target, cambia priorità. È un dettaglio UX, ma sposta l’uso verso cicli brevi di controllo.
Esempi in cui lo noti in 30 secondi:
→ sta scrivendo troppo: “taglia a 12 righe, fammi solo decisioni + next steps”
→ ha capito male il pubblico: “stai scrivendo per clienti finali, non per dev”
→ sta scegliendo il formato sbagliato: “non testo, tabella con 5 colonne”
Ricevi una guida pratica ogni settimana. AI, tool e automazioni.
Due punti da portarsi a casa se costruisci prodotti:
→ computer‑use general purpose: interazione via screenshot e comandi mouse/tastiera (non solo “scrivere codice”).
→ tool search: invece di caricare tutte le definizioni tool nel prompt, il modello parte con una lista “leggera” e carica la definizione solo quando serve.
OpenAI cita un test su MCP Atlas: tool search riduce il token usage del 47% a parità di accuratezza (nel loro setup).
Prezzi per 1M token (input, cached input, output). Fonte: OpenAI API pricing e tabella completa su developers.
| Modello | Input (1M) | Cached input (1M) | Output (1M) |
|---|---|---|---|
| gpt‑5.4 | $2.50 | $0.25 | $15.00 |
| gpt‑5.4‑pro | $30.00 | — | $180.00 |
| gpt‑5.2 | $1.75 | $0.175 | $14.00 |
| gpt‑4.1‑mini | $0.40 | $0.10 | $1.60 |
Nota pratica: nei sistemi “agentici” spesso il costo non è il modello. È la tua architettura di contesto (definizioni tool, log, allegati, RAG buttato dentro a caso). GPT‑5.4 spinge su tool search proprio per togliere quella tassa fissa.
OpenAI riporta miglioramenti su benchmark di knowledge work, coding, computer use e tool use. Qui sotto lo screenshot che gira come riassunto rapido. Se vuoi citare numeri, meglio sempre linkare la pagina ufficiale (settaggi e date contano).
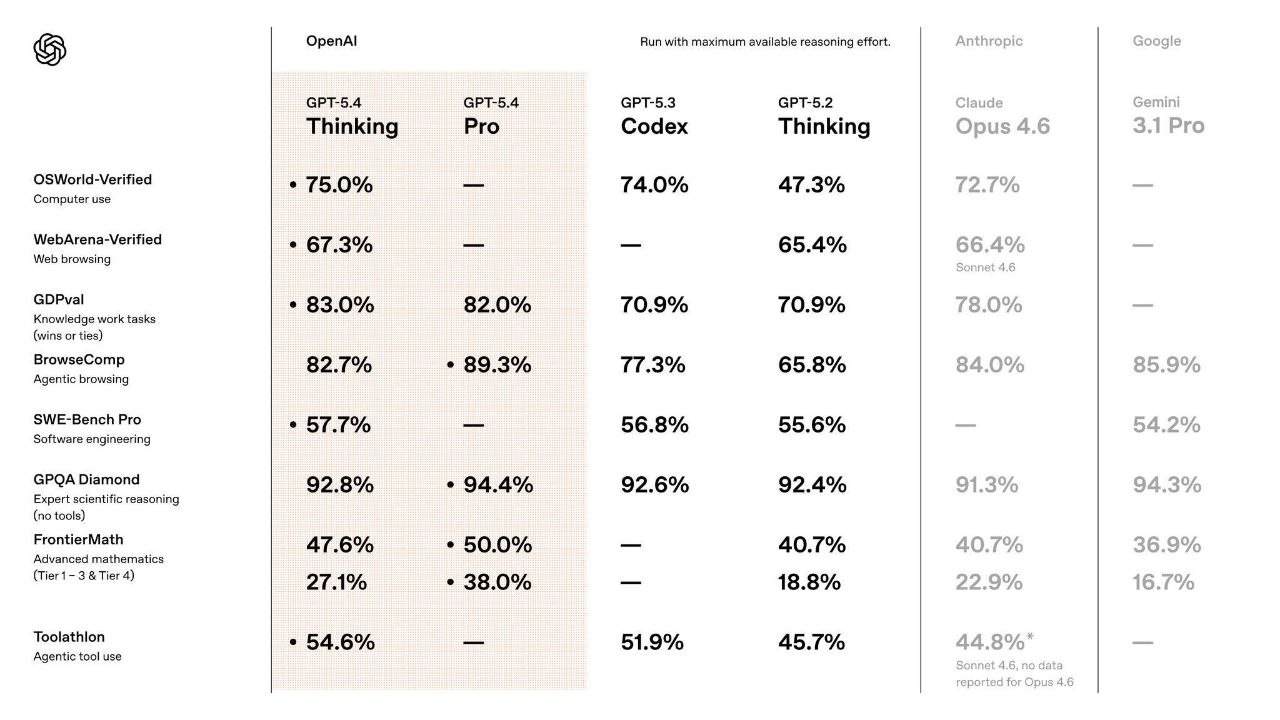
Tre prove con input reali. L’obiettivo non è “wow”. È capire se ti fa risparmiare tempo senza farti pagare in errori.
1) Documento
→ note riunione sporche → output: 1 pagina con decisioni, rischi, next actions.
→ misura: omissioni, errori fattuali, chiarezza.
2) Foglio
→ scenario con formule e edge case (sconti, IVA, regole) → output: tabella + formule + 3 casi limite.
→ misura: formule e coerenza, spiegazioni brevi.
3) Workflow con tool
→ compito a step (cerca, confronta, verifica, produce) con richiesta di fonti.
→ misura: usa tool quando serve, verifica davvero, non si perde.
Se GPT‑5.4 spinge su agenti e computer‑use, la domanda non è più “quanto è smart”. È quali permessi gli dai, che cosa può fare da solo e che log/audit hai quando qualcosa va storto.
Qui entra il contesto: negli stessi giorni del lancio, OpenAI è stata criticata per un accordo con il Pentagono (Department of War) per l’uso dei modelli in ambienti classificati. Il tema non è “AI sì/AI no”. Il tema è governance: chi decide i confini, chi verifica l’uso reale, e cosa succede quando la definizione di “uso consentito” cambia (o viene interpretata in modo aggressivo).
OpenAI ha parlato di “red lines” (niente sorveglianza domestica di massa, niente armi autonome, niente decisioni automatizzate ad alto impatto) e poi ha aggiornato il testo dell’accordo per chiarire meglio cosa intende per divieto di sorveglianza. Le critiche, però, si concentrano su un punto semplice: in ambito nazionale/militare la differenza la fanno i dettagli. Parole come “intenzionale”, “deliberato”, “conforme alla legge” possono essere abbastanza elastiche da lasciare spazio a pratiche che, agli occhi delle persone, sono comunque sorveglianza.
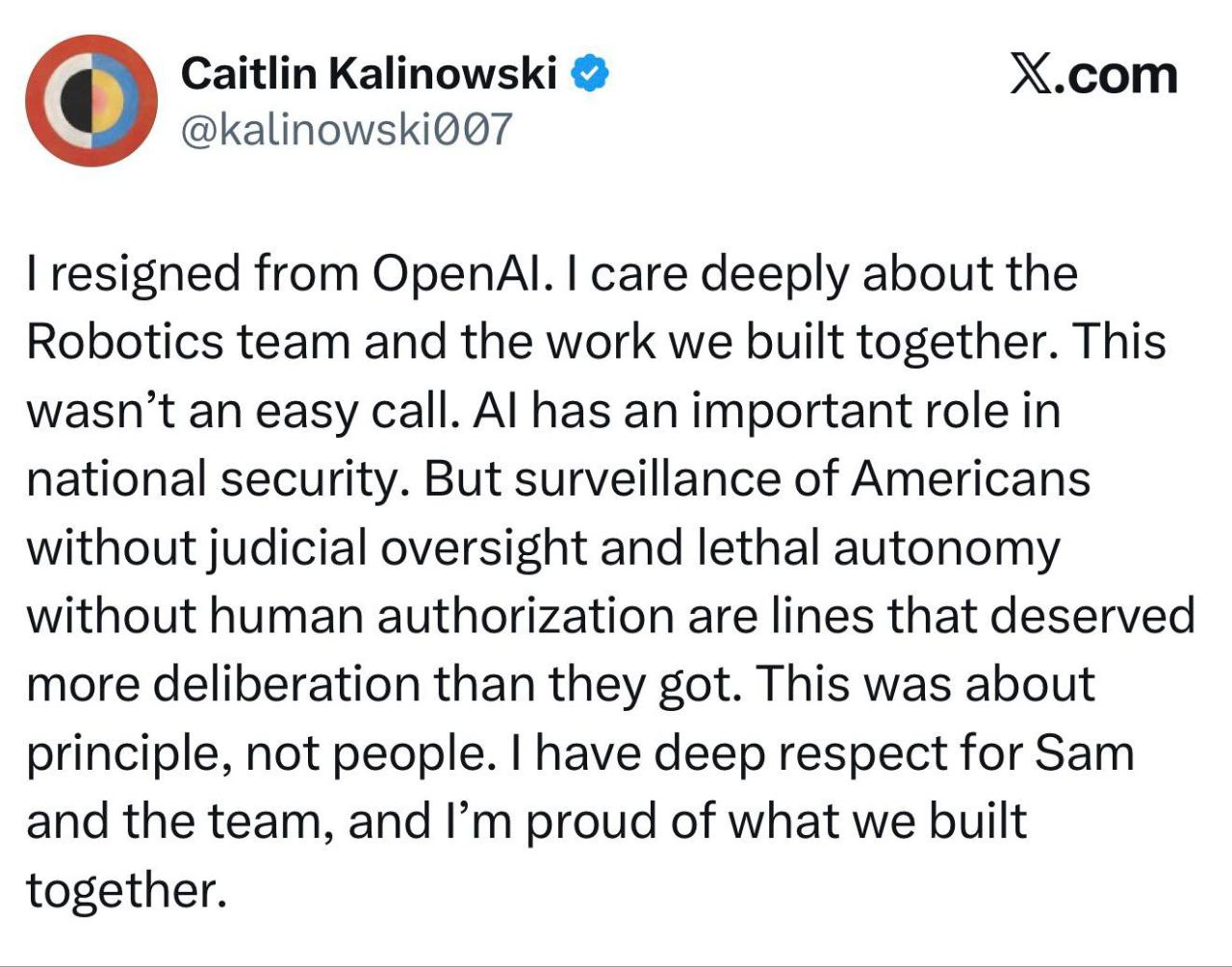
In mezzo a questa discussione, la responsabile robotics Caitlin Kalinowski ha annunciato le dimissioni dicendo (in sostanza) che sorveglianza senza supervisione giudiziaria e autonomia letale senza autorizzazione umana sono linee che avrebbero meritato più deliberazione. È un segnale utile da leggere così: gli agenti non sono solo feature. Sono permessi, responsabilità e rischio reputazionale.
→ Annuncio GPT‑5.4: openai.com
→ Prezzi API: openai.com
Se leggi spesso i miei articoli su AI, automazione e tecnologia, ora puoi dire a Google che vuoi vedere più spesso i contenuti di francescogruner.it tra le notizie.