Scopri come installare e utilizzare Gemma 3n con Hugging Face, Ollama e LM Studio. Funzionalità, multimodalità, trascrizione e chatbot in locale.
Google ha rilasciato ufficialmente Gemma 3n, il suo nuovo modello open source di AI multimodale progettato per girare direttamente su smartphone, laptop e dispositivi edge, anche con risorse limitate.
A differenza di modelli come Gemini, Gemma 3n è destinato alla comunità degli sviluppatori e può essere usato offline, in locale, senza invio dati al cloud.
Supporta input testo, immagini, audio e video, ed è già disponibile su:
- Ollama (CLI locale)
- LM Studio (interfaccia grafica)
- Hugging Face (per esecuzione via API o notebook)
- Google AI Studio (per test rapidi in cloud)
Perché Gemma 3n è rilevante
Gemma 3n introduce una nuova generazione di AI locale, multimodale e ottimizzata per dispositivi a bassa potenza. Ecco perché vale la pena provarlo:
✅ Multimodalità nativa
Accetta input testuali, immagini, audio e video, ed è progettato per generare solo output testuali (descrizioni, riassunti, Q&A, trascrizioni).
🧠 Architettura avanzata (MatFormer + PLE)
Attiva dinamicamente solo i parametri necessari, ottimizzando qualità e tempi di risposta. Include anche un modello 2B “nascosto” nel 4B, attivabile secondo necessità.
💾 Efficiente anche con 2 GB di RAM
Grazie a tecnologie come embedding per layer (PLE) e caching locale, funziona anche su dispositivi con risorse limitate (es. E2B).
⚡ Performance elevate
Fino a 1.5x più veloce rispetto a Gemma 3 4B su mobile. Ideale per esecuzioni in tempo reale.
🖼️ Vision encoder MobileNet-V5
Elabora immagini e video con maggiore precisione e velocità.
🌐 Supporto multilingua avanzato
Oltre 140 lingue testuali supportate, con prestazioni eccellenti in giapponese, tedesco, spagnolo, francese e coreano.
🔒 Privacy by design
Funziona completamente offline, senza invio dati. Ideale per applicazioni sensibili alla privacy.
🧵 Finestra di contesto estesa
Gestisce fino a 32.000 token per analisi di documenti complessi o input concatenati multimodali.
🏠 Caching intelligente
Riduce il consumo di memoria memorizzando in locale i parametri più usati.
📊 Benchmark superiori
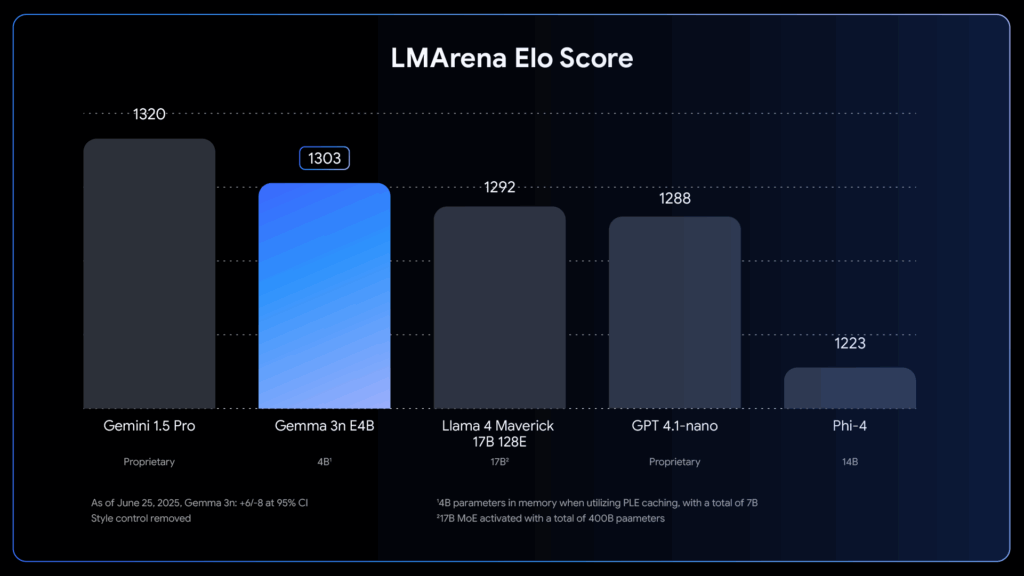
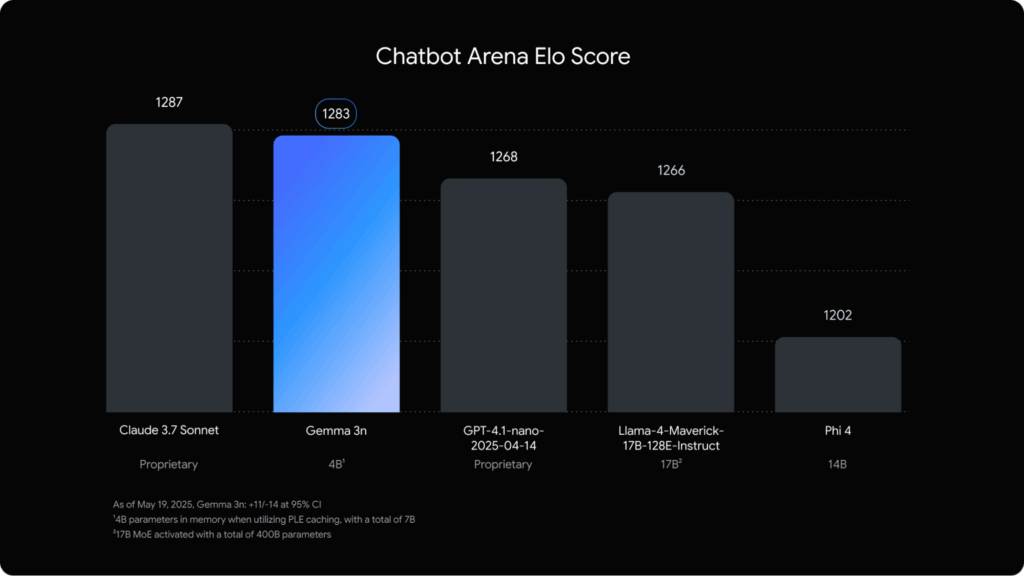
Nei test LMArena e Chatbot Arena, Gemma 3n ha superato modelli come LLaMA 4 Maverick 17B e GPT-4.1-nano.
📱 Compatibilità universale
Può essere eseguito su smartphone, Raspberry Pi, laptop e dispositivi edge con o senza GPU.
Benchmark ufficiali
LMArena Elo Score
Chatbot Arena Elo Score
Come usare Gemma 3n in locale
Ollama (per chi preferisce il terminale)
Come installarlo
Vai su ollama.com/download e scegli la versione per il tuo sistema operativo.
oppure:
curl -fsSL https://ollama.com/install.sh | shScarica il modello
ollama pull gemma3n:e2b # versione leggera (2GB RAM)
ollama pull gemma3n:e4b # più potente (3-4GB RAM)Avvia
ollama run gemma3n:e4bScrivi un prompt:
Analizza questo testo e fammi un riassunto in 3 punti.Fargli leggere un file
📄 File di testo
cat documento.txt | ollama run gemma3n:e4bpdftotext documento.pdf - | ollama run gemma3n:e4b🔉Audio (con Whisper)
whisper audio.mp3 --model base --language it
cat audio.txt | ollama run gemma3n:e4b🖼️ Immagine (workaround)
- Converti l’immagine in Base64
- Incollala nel prompt: “Questa è un’immagine in base64: […]. Cosa rappresenta?”
- Oppure usa LM Studio (vedi sotto)
Esempi di script Python
Script 1 – Analisi di un file .txt:
from ollama import Client
client = Client()
with open("documento.txt") as f:
testo = f.read()
response = client.chat(model="gemma3n:e2b", messages=[{"role": "user", "content": testo}])
print(response['message']['content'])Script 2 – Analisi immagine in base64:
import base64
from ollama import Client
with open("immagine.jpg", "rb") as img:
img64 = base64.b64encode(img.read()).decode()
prompt = f"Descrivi l'immagine: {img64}"
response = Client().chat(model="gemma3n:e4b", messages=[{"role": "user", "content": prompt}])
print(response['message']['content'])LM Studio (con interfaccia visuale, anche per immagini/audio)
Perfetto per chi vuole usare modelli localmente senza terminale, drag&drop per file multimediali.
Come si fa:
- Scarica LM Studio: lmstudio.ai
- Cerca “gemma-3n-e4b”
- Clicca “Use Model in LM Studio”
- Trascina file audio/immagini o inserisci prompt
Hugging Face (per setup avanzati o esperimenti in Colab)
Esegui su Colab o localmente con bitsandbytes, text-generation-webui, vLLM o Axolotl.
from transformers import AutoTokenizer, AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained("google/gemma-3n-e2b")
tokenizer = AutoTokenizer.from_pretrained("google/gemma-3n-e2b")Google AI Studio (per test rapidi senza installazioni)
Se preferisci testare Gemma 3n senza installazioni locali o requisiti hardware, puoi farlo direttamente in cloud grazie a Google AI Studio.
Non serve una GPU e l’accesso è immediato: ti basta un account Google.
👉 Clicca qui per provare Gemma 3n su Google AI Studio
In pochi secondi sarai operativo e potrai sperimentare con prompt testuali, immagini e altro ancora, sfruttando le potenzialità del modello in modalità serverless, gratuita e ufficiale.
Confronti e prestazioni
| Modello | Parametri effettivi | RAM richiesta | Multimodalità | Finestra contesto | Privacy |
|---|---|---|---|---|---|
| Gemma 3n E2B | 5B → 2B effettivi | 2 GB | ✅ Testo/Audio/Immagini | 32K token | ✅ Offline |
| LLaMA 3 8B | 8B | 6-8 GB | ❌ Solo testo | 8K-32K | ❌ |
| Qwen 4B | 4B | 3-4 GB | Parziale | 32K | ❌ |
| GPT-4o | ~1.8T | Cloud-only | ✅ ma online | 128K | ❌ |
Chi dovrebbe usare Gemma 3n
Questo modello è pensato per chi desidera il controllo completo, alte performance e flessibilità d’uso anche su dispositivi meno potenti:
- Ideale per sviluppatori con PC modesti: grazie all’architettura MatFormer e alla memoria ottimizzata (PLE), gira anche su laptop senza GPU.
- Perfetto per chi vuole privacy e AI offline: eseguibile localmente, senza invio dati a server esterni.
- Utile per app mobile, embedded e Raspberry Pi: ottimizzato per funzionare su dispositivi con risorse ridotte e sistemi edge.
Documentazione tecnica ufficiale
Conclusione
Gemma 3n rappresenta un punto di svolta per l’intelligenza artificiale in locale, multimodale e responsabile. È pronto per girare su notebook, tablet, smartphone o Raspberry, e offre prestazioni inaspettatamente avanzate, anche senza connessione internet.
Se vuoi un modello per trascrivere audio, riassumere documenti, analizzare immagini e interagire in linguaggio naturale, Gemma 3n è il candidato perfetto da testare nel 2025.