# MiniMax M2: cos’è, quanto costa e come usarlo
> Fonte: https://francescogruner.it/minimax-m2-cose-quanto-costa-e-come-usarlo/
MiniMax M2 è un modello di intelligenza artificiale **open-weight** (licenza MIT) con architettura **Mixture-of-Experts**: **230 miliardi** di parametri totali, **10 miliardi** attivi per token. Nasce per **scrivere codice** e **usare strumenti** (terminale, browser, interprete Python) in autonomia. Supporta **contesti fino a 200.000 token**, è **rapido** ed **economico**, e si integra sia **via API** sia **in locale**. Se costruisci **agenti** o **assistenti per sviluppatori**, è una scelta solida per POC e produzione.
Indice dei contenuti
[Toggle](#)
- [Cos’è MiniMax M2](#Cose_MiniMax_M2)
- [Quando conviene (e quando no)](#Quando_conviene_e_quando_no)
- [Ti sta piacendo?](#Ti_sta_piacendo)
- [Quanto costa davvero (e cosa misurare)](#Quanto_costa_davvero_e_cosa_misurare)
- [4) Provarlo subito con Ollama Cloud](#4_Provarlo_subito_con_Ollama_Cloud)
- [Integrarlo via API con OpenRouter (per ora free)](#Integrarlo_via_API_con_OpenRouter_per_ora_free)
- [Eseguirlo in casa (self-host): vLLM e SGLan](#Eseguirlo_in_casa_self-host_vLLM_e_SGLan)
- [vLLM (server OpenAI-compatible)](#vLLM_server_OpenAI-compatible)
- [SGLang (molto reattivo per agenti)](#SGLang_molto_reattivo_per_agenti)
- [Provalo ora con DeepSite (gratis su Hugging Face)](#Provalo_ora_con_DeepSite_gratis_su_Hugging_Face)
- [Esempio pratico: “correggi un bug e apri una PR”](#Esempio_pratico_%E2%80%9Ccorreggi_un_bug_e_apri_una_PR%E2%80%9D)
- [Problemi comuni e soluzioni](#Problemi_comuni_e_soluzioni)
- [Valutare le prestazioni (metriche chiare)](#Valutare_le_prestazioni_metriche_chiare)
- [Sicurezza, governance, cost control](#Sicurezza_governance_cost_control)
- [Domande frequenti (FAQ)](#Domande_frequenti_FAQ)
- [Risorse ufficiali (link diretti)](#Risorse_ufficiali_link_diretti)
## Cos’è MiniMax M2
- **Tipo**: LLM con **pesi pubblici** (licenza MIT).
- **Architettura**: **MoE “sparsa”** → grande capacità totale, ma attiva solo una piccola parte per token (meno latenza e costi).
- **Focus**: coding multi-file, cicli *edit → run → fix → test*, agenti con **tool-calling** (terminal, browser, Python/MCP).
- **Contesto**: fino a **~200K token** (dipende dal serving scelto).
- **Interleaved thinking**: il modello inserisce un blocco di ragionamento `…` che **deve rimanere** nella cronologia. Se lo togli, peggiorano pianificazione e coerenza.
## Quando conviene (e quando no)
**Usalo se**:
- vuoi **agenti multi-step** che orchestrano shell + browser + Python/MCP;
- ti serve un **assistente dev end-to-end** (fino all’apertura della PR);
- lavori con **contesti lunghi** (log, manuali, trascrizioni, lunghi thread tecnici).
**Valuta alternative se**:
- il carico è **ragionamento matematico puro** (competizioni/olimpiadi);
- policy/stack **impediscono** di salvare `` tra i turni.
## Ti sta piacendo?
Ricevi una guida pratica ogni settimana. AI, tool e automazioni.
Iscriviti gratis Perfetto, sei dentro.
## Quanto costa davvero (e cosa misurare)
Indicazioni tipiche API: **~$0,30/M token input**, **~$1,20/M token output**.
Conta **il costo per task** (quanto paghi per chiudere il lavoro), non il prezzo “al milione” preso da solo.
**Esempio**: 120.000 token in + 80.000 token out
- IN: 120.000 × 0,30 / 1.000.000 = **$0,036**
- OUT: 80.000 × 1,20 / 1.000.000 = **$0,096**
- **Totale task**: **$0,132**
**Consigli**
- Metti un **cap** agli output token.
- **Logga** token IN/OUT di **tutte** le chiamate.
- Conta i **retry** (step rifatti: test falliti, tool-error, piano rivisto).
Riferimenti API: [https://platform.minimax.io/docs/guides/pricing#text](https://platform.minimax.io/docs/guides/pricing#text)
## 4) Provarlo subito con **Ollama Cloud**
Ollama Cloud: come avviare MiniMax-M2 dal terminale con ollama run minimax-m2:cloud. La scheda mostra il profilo del modello e il contesto 200K.
> Prova lampo da terminale, nessun peso da scaricare.
**Comando**
```
ollama run minimax-m2:cloud
```
**Note**
- Gira **in cloud** (non locale).
- Contesto ~**200K**.
- Script rapido:
```
echo "Spiegami come risolvere l'errore X" | ollama run minimax-m2:cloud
```
**Pagina modello**: [https://ollama.com/library/minimax-m2](https://ollama.com/library/minimax-m2)
**Pro**: parti in 30 secondi.
**Contro**: meno controllo su latenza/rete; non è un endpoint API “universale”.
## Integrarlo via API con **OpenRouter** (per ora free)
> Endpoint **compatibile OpenAI**, perfetto per app, bot, IDE, n8n.
**Python**
```
from openai import OpenAI
client = OpenAI(
base_url="https://openrouter.ai/api/v1",
api_key="",
)
res = client.chat.completions.create(
model="minimax/minimax-m2:free",
messages=[
{"role":"system","content":"Sei un assistente per coding e tool-use."},
{"role":"user","content":"Scrivi un test che riproduce il bug #123 e proponi la patch."}
],
temperature=1.0,
top_p=0.95
)
print(res.choices[0].message.content)
```
**Curl**
```
curl https://openrouter.ai/api/v1/chat/completions \
-H "Authorization: Bearer $OPENROUTER_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model":"minimax/minimax-m2:free",
"messages":[
{"role":"system","content":"Assistant per coding/agent."},
{"role":"user","content":"Genera un piano passo-passo per correggere il test fallito e preparare la PR."}
],
"temperature":1.0,
"top_p":0.95
}'
```
**Pagina modello**: [https://openrouter.ai/minimax/minimax-m2:free](https://openrouter.ai/minimax/minimax-m2:free)
**Parametri consigliati**: `temperature 1.0`, `top_p 0.95`, `top_k 40` (A/B con 20).
**Cruciale**: **non filtrare** `` quando invii la cronologia del turno successivo.
**Pro**: integrazione veloce; al momento **gratis**; throughput/latency buoni.
**Contro**: la gratuità può cambiare → prevedi **fallback** a versione paid o self-host.
## Eseguirlo in casa (self-host): **vLLM** e **SGLan**
**Pesi e doc**
- Hugging Face: [https://huggingface.co/MiniMaxAI/MiniMax-M2](https://huggingface.co/MiniMaxAI/MiniMax-M2)
- GitHub (guide): [https://github.com/MiniMax-AI/MiniMax-M2](https://github.com/MiniMax-AI/MiniMax-M2)
- News: [https://www.minimax.io/news/minimax-m2](https://www.minimax.io/news/minimax-m2)
### vLLM (server OpenAI-compatible)
> Indicativamente **40–80 GB VRAM** a seconda di dtype/quantizzazione/parallelismi.
```
pip install "vllm>=0.6.0.dev0"
python -m vllm.entrypoints.openai.api_server \
--model MiniMaxAI/MiniMax-M2 \
--dtype auto \
--gpu-memory-utilization 0.9 \
--max-model-len 200000 \
--trust-remote-code
```
**Ottimizzazioni**: PagedAttention (default), batching dinamico, KV-cache, FP8/INT8 (quando stabile), tensor/pipeline parallel, speculative decoding (se disponibile).
### SGLang (molto reattivo per agenti)
```
pip install "sglang>=0.3.0"
sglang serve \
--model MiniMaxAI/MiniMax-M2 \
--context-length 200000 \
--trust-remote-code
```
**Tip**: abilita *chunk prefill* per contesti lunghi e **logga la tool-latency** (plan → act → verify) per trovare i colli di bottiglia.
## Provalo **ora** con DeepSite (gratis su Hugging Face)
Vuoi “giocarci” senza installare nulla e generare codice/front-end al volo?
Usa **DeepSite – Vibe Coding**: [https://huggingface.co/spaces/enzostvs/deepsite](https://huggingface.co/spaces/enzostvs/deepsite)
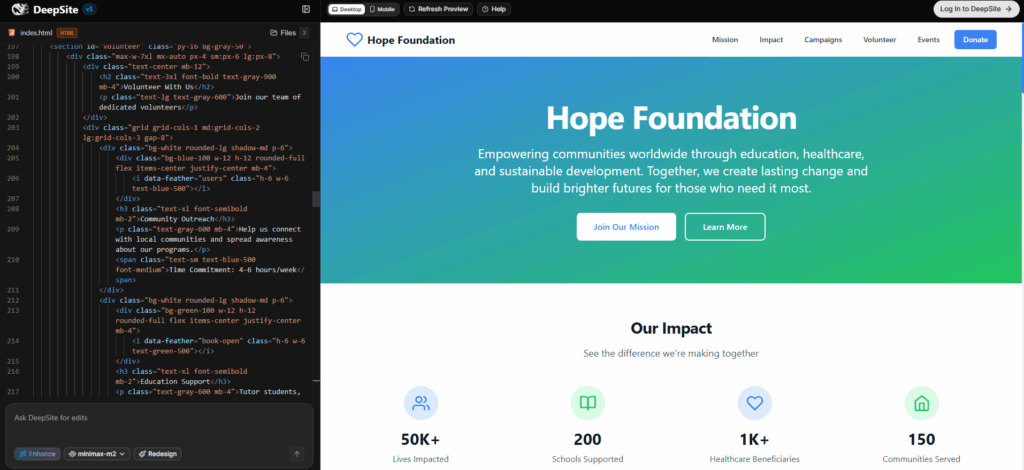
**Come fare (2 minuti):**
1. Apri lo Space e clicca su **Start Vibe Coding** (se serve, wake up).
2. In **Customize Settings**, scegli **MiniMax M2** come modello (provider auto).
3. Scrivi cosa vuoi creare (es. “Landing page responsive con hero, pricing e CTA”).
4. Premi **Run**: DeepSite genera il progetto e puoi modificare/rigenerare sezioni.
5. Esporta i file o copia il codice nel tuo IDE.
**Perché è utile**: è il modo più semplice e gratuito per testare MiniMax-M2 su un flusso di **coding reale** (UI/HTML/CSS/JS) prima di integrarlo nelle tue pipeline.
## Esempio pratico: “correggi un bug e apri una PR”
**System (una volta sola)**
```
Sei un agente di sviluppo. Strategia: pianifica → agisci → verifica.
Strumenti: terminale, interprete Python, browser. Log sintetici.
Limiti: massimo 100 comandi; apri PR solo se i test sono verdi.
```
**User**
```
Repo:
Obiettivo: riprodurre il bug #123, scrivere un test, applicare la patch, rieseguire i test.
Consegna: diff, breve spiegazione tecnica, link alla PR.
```
**Loop tipico**
1. Pianifica (nel ``).
2. Esegui i test.
3. Leggi gli errori.
4. Applica la patch.
5. Ritesta.
6. Commit + PR se tutto verde.
> **Non rimuovere** `` dalla cronologia: serve a mantenere il piano.
## Problemi comuni e soluzioni
- **Calano le performance dopo pochi turni** → quasi sempre hai rimosso ``. Conservalo (puoi **nasconderlo in UI**, ma **salvalo** lato server).
- **Latenza alta con molte tool-call** → riduci verbosità tra gli step, abilita batching/speculative, preferisci **SGLang** per hop frequenti.
- **Token OUT elevati** → metti **hard-cap** agli output, chiedi **riassunti periodici** dei log, taglia history superflue.
- **Errori su matematica/logic “dura”** → usa tool **Python** per i calcoli e, quando serve, **2–3 tentativi** con selezione del migliore.
## Valutare le prestazioni (metriche chiare)
Tieni sempre queste **4 metriche**:
1. **Tempo totale**: minuti dall’inizio alla fine del task.
2. **Token IN/OUT**: somma dei token di **tutte** le chiamate del task.
3. **Retry**: step rifatti (test falliti, tool error, piano rivisto).
4. **€ per task**:
> `costo_task = (token_in_tot * prezzo_in/M + token_out_tot * prezzo_out/M) / 1.000.000`
**Esempio tabella (SWE-bench: 3 issue)**
TaskEsitoMinutiToken INToken OUTRetryCosto123Pass18,4121.00084.00020,1377Fail22,9160.000112.00040,239Pass14,698.00062.00010,10
**Medie rapide**: **pass-rate**, **tempo medio**, **costo medio**.
Sono i numeri che aiutano davvero a decidere (CTO/CFO).
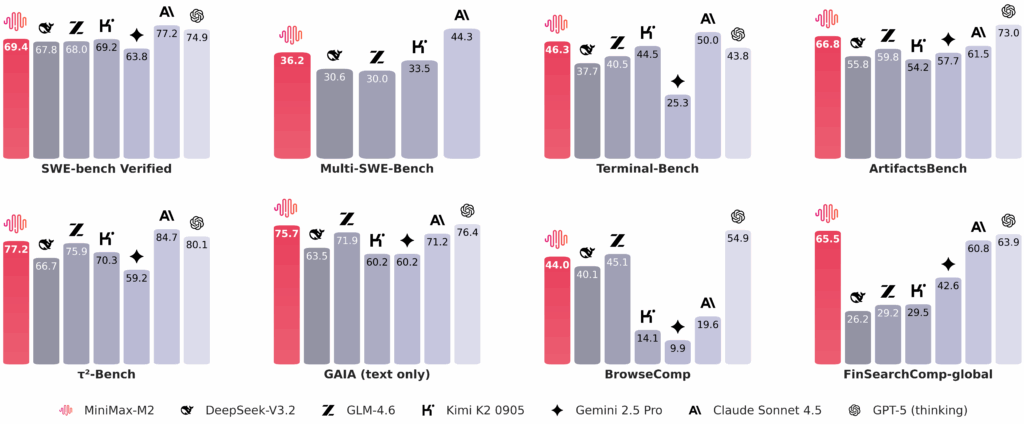
Confronto sintetico delle prestazioni su suite pratiche di coding e tool-use.
## Sicurezza, governance, cost control
- **Tool policy**: allow-list dei domini, sandbox Python, limiti shell.
- **Audit**: salva plan/act/verify e citazioni web.
- **Segreti/PII**: non farli comparire nel ``; usa un **vault**.
- **Budget**: alert su **token OUT** e limiti per job.
- **Privacy**: dati sensibili? Meglio **self-host**.
## Domande frequenti (FAQ)
**È migliore dei modelli proprietari top?**
Su tool-use e coding è **competitivo**; sul ragionamento matematico puro in genere no. Decidi con il **costo per task**.
**Devo davvero conservare ``?**
Sì: MiniMax-M2 è progettato per **interleaved thinking**. Se lo togli, degradano pianificazione e coerenza.
**Supporta MCP e strumenti esterni?**
Sì: terminale, browser, Python sono *first-class*; MCP è uno scenario naturale.
**Quanta GPU serve on-prem?**
Dipende da dtype/quantizzazione. Con **FP8/INT8** e parallelismi puoi ridurre la VRAM, ma verifica sempre la **latenza tail** rispetto ai tuoi SLO.
## Risorse ufficiali (link diretti)
- **OpenRouter (free, endpoint OpenAI-compatible)**: [https://openrouter.ai/minimax/minimax-m2:free](https://openrouter.ai/minimax/minimax-m2:free)
- **News/Annuncio MiniMax-M2**: [https://www.minimax.io/news/minimax-m2](https://www.minimax.io/news/minimax-m2)
- **Ollama Cloud – pagina modello**: [https://ollama.com/library/minimax-m2](https://ollama.com/library/minimax-m2)
- **Hugging Face – pesi**: [https://huggingface.co/MiniMaxAI/MiniMax-M2](https://huggingface.co/MiniMaxAI/MiniMax-M2)
- **Repository GitHub (guide, tool, doc)**: [https://github.com/MiniMax-AI/MiniMax-M2](https://github.com/MiniMax-AI/MiniMax-M2)