Ricevi la newsletter
Tool, prompt e workflow AI. Una volta a settimana, gratis.
Sei dentro. Da questa settimana ricevi la newsletter.
GLM-5 punta su agenti e task lunghi: numeri, limiti, cosa fa davvero (Office output) + link ufficiali per provarlo →

GLM-5 (Z.ai) arriva con un messaggio semplice: meno “chat”, più agenti e task lunghi. Tradotto: lavori che non si chiudono in 2 prompt e che mettono in crisi i modelli quando devono pianificare, usare tool e non perdere il filo.
Qui non mi interessa il numerino “da leaderboard”. Mi interessa se regge quando lo metti a fare sistemi: più componenti, più vincoli, più passi, più errori da recuperare.
→ se non hai una toolchain decente (guardrail, logging, retry, timeouts), un modello “più agentico” ti produce casino più velocemente
→ se lo vuoi davvero “in casa”, serving e memoria contano più del marketing: GLM-5 è grosso, e va trattato come un pezzo d’infrastruttura.
Z.ai lo posiziona così: 744B parametri totali in MoE, 40B attivi. Rispetto a GLM-4.5 parla di salto sia di scala sia di dati (da 23T a 28.5T token), con due scelte tecniche che tornano spesso:
→ DSA (DeepSeek Sparse Attention) per tenere il long context senza bruciarsi i costi di serving
→ slime: infrastruttura RL asincrona per accelerare il post-training (meno iterazioni “lente”, più cicli)
Ricevi una guida pratica ogni settimana. AI, tool e automazioni.
Il pezzo più interessante del lancio non è “ragiona meglio”. È che insistono su orizzonti lunghi. E su Vending Bench 2 dicono di essere #1 tra gli open source: simulazione di un vending business su un anno, con un risultato finale (saldo) che loro mettono a confronto con modelli chiusi.
Note pratiche (senza benchmark)
→ quando deve generare UI complete (layout + componenti + micro-interazioni), di solito regge bene
→ quando il task diventa “simulazione/gioco”, il rischio è l’opposto: bella faccia, logica fragile
→ se lo usi in tool e automazioni: valuta sempre stato, error recovery e retry, non solo la prima risposta
Uno dei punti più concreti del posizionamento Z.ai non è “scrive meglio”. È output da consegnare: documenti e file pronti (Word/Excel/PDF), non solo testo in chat. Qui sotto c’è un esempio ufficiale: un .docx generato da GLM-5.
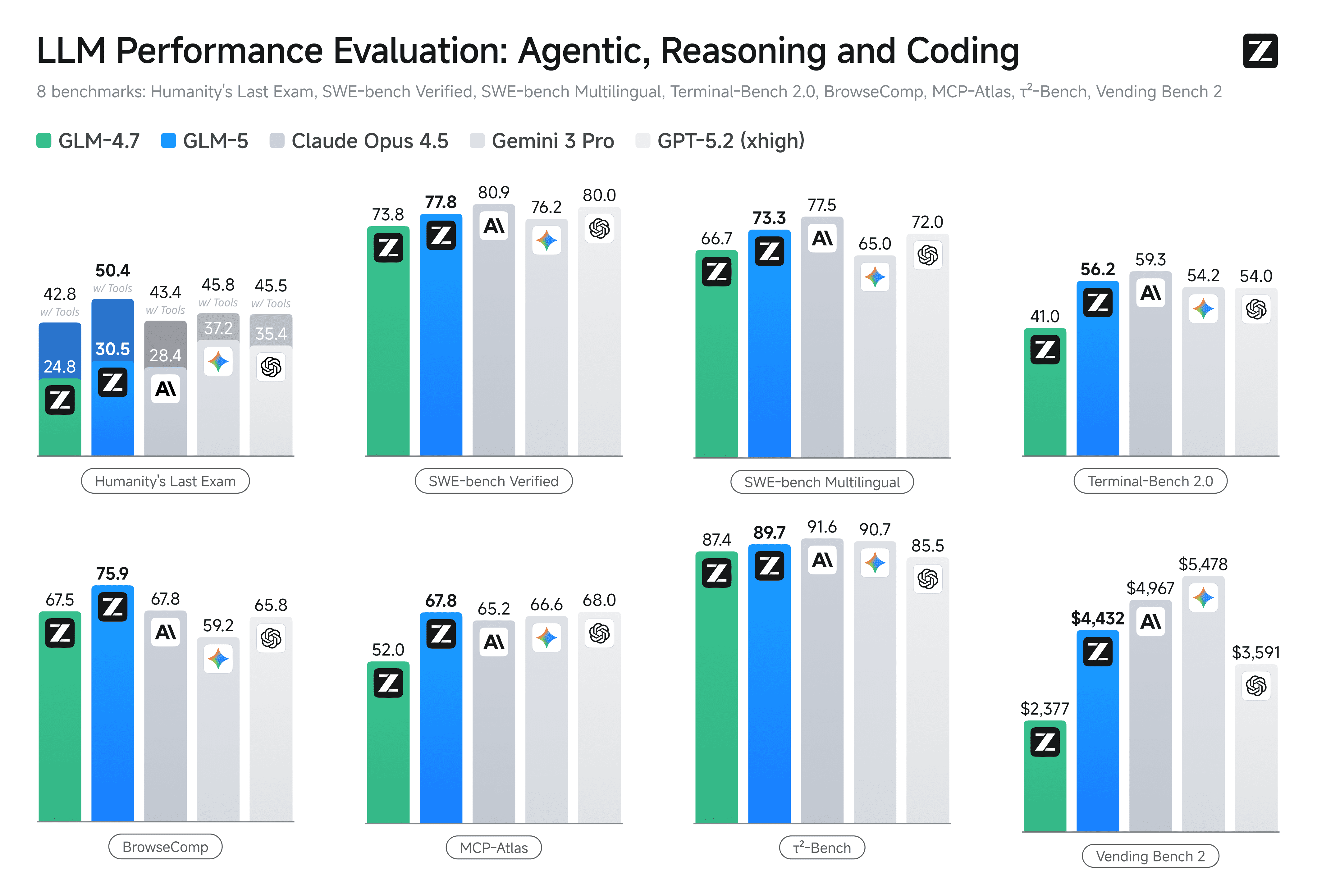
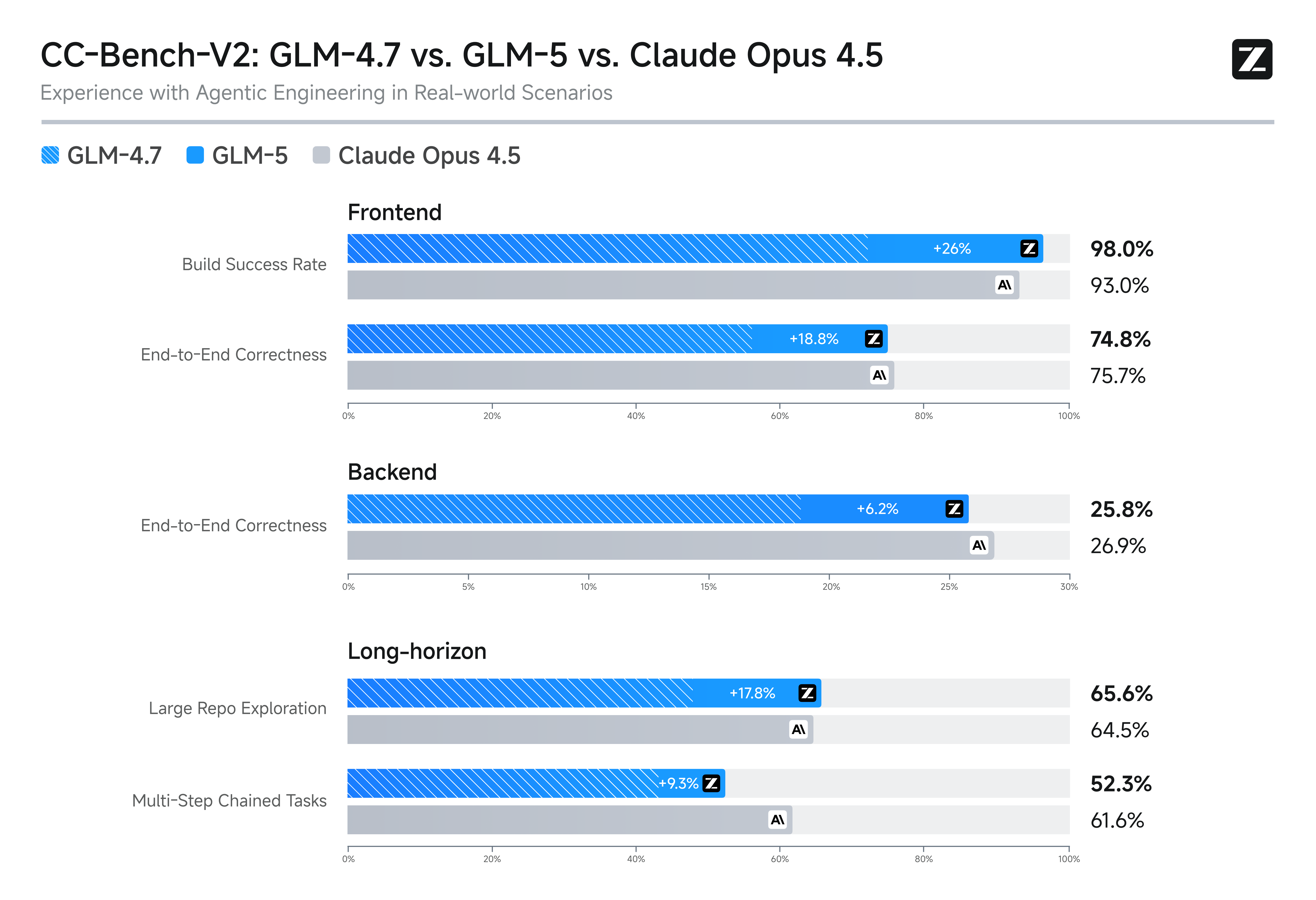
Due grafici ufficiali Z.ai: li uso solo per inquadrare il posizionamento (non per fare tifo).
→ takeaway 1: spingono su agenti e task lunghi
→ takeaway 2: mostrano benchmark “macro” + suite interna (CC-Bench-V2)
Due grafici ufficiali Z.ai, messi qui per dare contesto al claim “agenti + task lunghi”. Prendili come posizionamento, non come sentenza.
Se ti serve una demo “da capire al volo”: qui l’output è un .docx pronto, non un muro di testo. Fonte: Z.ai.
Qui il take pratico è semplice: se il tuo uso è “scrivimi una mail”, non te ne accorgi. Se invece fai automazioni, deployment, analisi log, tool use e task multi-step, questo è il terreno dove o ti salva tempo o ti fa perdere giornate.
GLM-5 è rilasciato con licenza MIT. Se vuoi vederlo e toccarlo subito:
→ chat ufficiale: chat.z.ai
→ API: docs.z.ai (GLM-5)
→ repo: zai-org/GLM-5 su GitHub
→ pesi: GLM-5 su Hugging Face
→ Ollama Cloud: ollama.com/library/glm-5
→ provider (API pronta): OpenRouter (GLM-5)
Nota pratica: se non hai già GPU + serving pronti, provarlo “in casa” è il modo più lento per capire se ti piace. Per test e uso quotidiano, chat/API/provider ti danno prestazioni più prevedibili e zero sbatti.
Se hai seguito la serie Z.ai/GLM qui sul sito: GLM-5 va letto come step successivo rispetto a GLM-4.6 e 4.6V:
Video: GLM-4.6 spiegato in 6 minuti
→ GLM-4.6 (Z.ai)
→ e qui: GLM-4.6V (tool calling in locale)
Se lo provi in chat o API, non farti fregare dai test “da bar”. Usa un task che ti somiglia:
Hai 3 tool: (1) search_logs(query), (2) apply_patch(file, diff), (3) run_tests().
Obiettivo: risolvere il bug senza rompere altro. Step obbligatori:
- fai un piano breve (5 righe max)
- poi esegui: prima search_logs, poi patch, poi run_tests
- se fallisce, fai retry con una sola ipotesi alla volta
- output finale: spiegazione + diff + comandi eseguiti→ Z.ai (post tecnico): https://z.ai/blog/glm-5
→ GitHub (repo + deploy): https://github.com/zai-org/GLM-5
→ Hugging Face (pesi): https://huggingface.co/zai-org/GLM-5
→ Paper: https://arxiv.org/abs/2602.15763
→ Docs API: https://docs.z.ai/guides/llm/glm-5
→ Provider (scheda): https://openrouter.ai/z-ai/glm-5
Se leggi spesso i miei articoli su AI, automazione e tecnologia, ora puoi dire a Google che vuoi vedere più spesso i contenuti di francescogruner.it tra le notizie.