Ricevi la newsletter
Tool, prompt e workflow AI. Una volta a settimana, gratis.
Sei dentro. Da questa settimana ricevi la newsletter.
Gemma 4 è finalmente uscito: il nuovo modello open source di Google DeepMind porta AI multimodale, reasoning avanzato e agent anche in locale. Ecco cosa cambia davvero, benchmark e come provarlo subito.

Gemma 4 è finalmente uscito, e questa volta non è il classico rilascio che guardi per curiosità e dimentichi dopo qualche giorno.
Google DeepMind ha preso quello che ha costruito con i modelli Gemini e lo ha portato nel mondo dei modelli AI open source con un approccio molto più concreto del solito.
Se fino a ieri gli open model erano spesso “buoni ma limitati”, qui iniziamo a vedere qualcosa di diverso: un modello pensato per lavorare davvero dentro sistemi, agent e automazioni.
E soprattutto, progettato per funzionare anche in locale.
Sulla carta, Gemma 4 ha tutte le caratteristiche che oggi ci aspettiamo:
Ma la differenza non è qui.
La differenza è che questo modello è stato chiaramente progettato per fare cose, non solo per rispondere bene.
Dai primi test emerge un comportamento molto più “operativo” rispetto ai classici chatbot: pianifica, utilizza strumenti, genera output strutturati e si integra bene in workflow reali.
È molto più vicino a un sistema come Claude Code che a una semplice chat.
Con un vantaggio non banale:
→ non sei obbligato a passare da API esterne
Guardando i numeri, il miglioramento rispetto alla generazione precedente è netto.
Ma la cosa interessante è che non resta nei benchmark.
Nei test reali il modello:
Sul coding in particolare si vede il salto: non si limita più a snippet, ma costruisce interfacce, pagine e simulazioni con una coerenza che, fino a poco tempo fa, era difficile trovare negli open model.
Ricevi una guida pratica ogni settimana. AI, tool e automazioni.
Uno degli aspetti più interessanti è la tenuta sui modelli piccoli.
Le versioni più leggere riescono già a:
Questo apre scenari concreti per:
→ document AI locale
→ automazioni su file e immagini
→ applicazioni su mobile
Non è perfetto, ovviamente.
Errori su task banali (tipo conteggi) ci sono ancora, e qualche comportamento strano sull’audio è stato segnalato.
Ma il punto è un altro:
→ funziona bene dove serve davvero
Gemma 4 non è un modello unico, ma una famiglia ben pensata.
Le versioni E2B ed E4B sono progettate per AI su smartphone e dispositivi locali. Sono leggere, multimodali e funzionano offline. Perfette per agent locali o sistemi embedded.
Salendo troviamo i modelli 26B e 31B, pensati per workstation e GPU consumer.
Qui spicca il 26B MoE (Mixture of Experts):
→ attiva solo una parte dei parametri
→ mantiene qualità alta
→ riduce costi e latenza
È probabilmente il modello più interessante per chi vuole costruire sistemi reali senza dover usare infrastrutture enormi.
Al di là della parte tecnica, il vero impatto è questo.
Con Gemma 4 diventa realistico costruire sistemi di intelligenza artificiale in locale senza dipendere completamente da provider esterni.
Questo significa:
Il cloud non sparisce, ma smette di essere l’unica opzione.
Se vuoi testarlo velocemente, puoi partire da qui:
👉 Google AI Studio
https://aistudio.google.com/prompts/new_chat?model=gemma-4-31b-it
Se invece vuoi usarlo davvero in locale, il modo più semplice è Ollama:
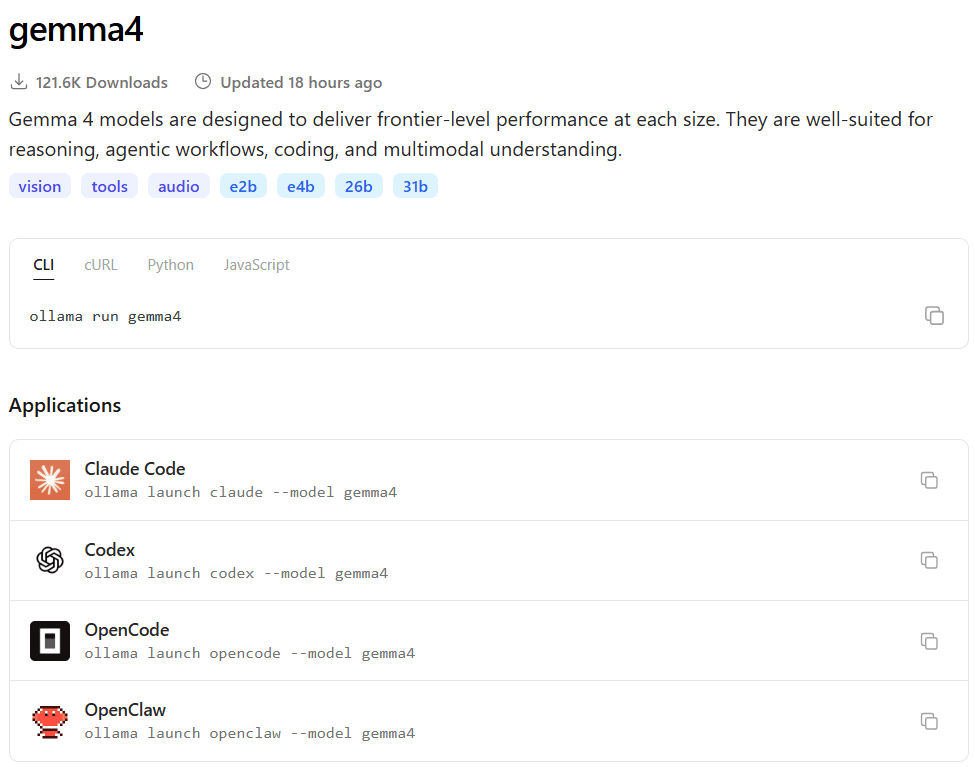
ollama run gemma4
Oppure:
ollama run gemma4:e2b
ollama run gemma4:26b
ollama run gemma4:31b
Per ambienti più avanzati puoi integrarlo con vLLM o Transformers.
Gemma 4 non è interessante perché è “un buon modello”.
È interessante perché:
→ porta capacità avanzate fuori dal cloud
→ rende l’AI locale una scelta reale, non un compromesso
→ apre scenari concreti per agent, SaaS e automazioni
Non è ancora perfetto e serviranno test più approfonditi.
Ma una cosa è chiara:
→ gli open model non sono più una seconda scelta
Se leggi spesso i miei articoli su AI, automazione e tecnologia, ora puoi dire a Google che vuoi vedere più spesso i contenuti di francescogruner.it tra le notizie.